

1. 서 론
2. 재료 및 방법
2.1 공시재료
2.2 증해
2.3 스펙트럼 데이터 수집
2.4 스펙트럼 데이터의 전처리
2.5 다변량 분석 및 기계학습 모델 생성
2.6 모델 성능 검증 및 평가
3. 결과 및 고찰
3.1 닥나무 인피섬유의 ATR-IR 스펙트럼
3.2 주성분 분석
3.3 PLS-DA
3.4 분류모델의 성능 비교
3.5 분류모델의 성능지표
4. 결 론
1. 서 론
국가기록물의 보존은 국민의 정체성과 국체의 정통성을 강화하는 등 문화선진국으로의 성장을 위한 초석이라 할 수 있다.1) 예로부터 우리나라의 고유 전통적 문화유산인 한지의 보존적 우수성은 사료의 보존상태와 현대 과학기술을 통해 입증된 바 있다.2) 한지의 주원료인 닥나무 인피섬유는 화학적 측면에서 목재 펄프에 비하여 셀룰로오스 섬유자체의 중합도가 높고 리그닌 함량이 현저히 낮으며, 물리적 측면으로는 섬유장이 길고 강인하다는 특징이 있다.1) 사계절이 뚜렷하고 일교차가 높은 우리나라 기후에서 성장한 닥나무 인피섬유의 경우 강도적 특성이 특히 우수하고 광택성이 뛰어나다.3) 반면 태국산 등 일부 수입산 닥나무 인피섬유의 경우 국산에 비하여 광택이나 탄력이 현저히 떨어진다는 특징을 갖는다.4)이처럼 같은 닥나무라고 할지라도 원산지의 기후, 풍토 조건, 일교차 정도 등에 따라 화학적 특성과 물리적 특성이 변화될 수 있다.
수작업으로 제조되는 한지는 제조공정상 시간을 단축시키기 위해 인피섬유 형태로 가공되어 유통되는 경우가 많으며 제법, 제조연도, 수급현황, 대외환경 등의 조건에 따라 품질 및 보존 특성이 변화한다.5) 현재까지 섬유 식별법으로서 이미지 분석, 물리적 특성 분석 등 간접적 및 파괴분석 등 신뢰도가 다소 떨어지며 비효율적 분석이 주를 이루어 왔다. 따라서 국내 보존과학 산업의 발전과 닥섬유 수급의 전문적 관리를 위해서는 섬유의 손상을 최소화하며 과학적인 분석법을 적용한 수종 및 원산지 판별 기술이 보급되어야 한다고 사료된다.
화학계량학(chemometrics)이란 스펙트럼이나 크로마토그램과 같은 다양한 분석화학 데이터에서 원하는 정보를 도출하여 정성 및 정량분석을 가능하게 하는 수학적 통계 알고리즘을 총칭하는 것으로 다변량 분석(multivariate analysis)과 함께 제품의 종류 및 원산지 판별, 진위 분석 등에 적용된다.6) 화학계량학에서 주로 이용되는 분광 분석은 분석 대상에 대한 파괴를 요하지 않아 보존과학적 접근에 있어 전도유망한 접근법이라 판단된다. 한지 및 닥섬유에 대한 화학계량학적 연구사례로는 Kim 등6)이 attenuated total reflection infrared spectroscopy (ATR-IR) 및 near Infrared spectroscopy (NIR)과 주성분분석(principal component analysis, PCA)을 적용하여 한·중·일 전통지의 분류분석을 진행한 바 있다. 그러나 화학계량학에서 사용되는 다변량 분석법의 경우 독립변수와 종속변수에 대한 선형관계를 가정하는 경우가 다수이기 때문에 예측 모델링을 위한 수단으로서는 부적합 할 수 있다. 또한 다중공선성으로 인한 적용 범위의 제한 역시 종래 다변량 모델의 한계로 지적되고 있는 실정이다.7,8)
기계학습 모델은 다변량 분석 모델의 제한점을 극복할 수 있는 효과적인 방법으로서 비선형적 혹은 대량의 복잡한 데이터 세트 내에서 보다 유리하게 작용한다. 한지와 닥섬유 분야에 대한 기계학습 모델링 연구사례로는 Jang 등5,9)이 NIR 스펙트럼 데이터와 대표적 기계학습 분류모델인 부분 최소 자승 판별 분석법(partial least squares discriminant analysis, PLS-DA), 서포트 벡터 머신(support vector machine, SVM) 및 랜덤 포레스트(random forest, RF)를 결합하여 초지 방법에 따른 한지 특성의 예측 모델링에 관한 연구를 보고한 바 있다. 또한 Hwang 등10)은 ATR-IR 데이터에 인공신경망(artificial neural network, ANN) 모델을 적용 시 한지 제조 지역에 대한 분류 분석과 원료 및 화학적 특성에 대한 예측 모델링이 가능할 수 있다고 보고하였다.
기계학습이 다변량 분석 모델에 비하여 강력한 도구인 것은 자명하나 다변량 분석 모델에 적용 범위를 전적으로 대체한다고 가정할 수는 없다. 따라서 두 접근 방법에 있어서는 상호보완적 접근이 요구되며 모델의 효율성을 개선할 수 있는 접근법을 탐색하는 것이 우선적인 요인일 수 있다.
스펙트럼 데이터 분석의 경우 분석 방법, 기기 자체의 드리프트 혹은 물리·화학 및 환경적 요인에 의거 다양한 변수가 작용한다.11) 특히 ATR-IR의 경우 base line과 scattering effect에 대한 재현성과 반복성이 부족하여 예측 모델링 시 복잡성을 증가시키고 모델의 견고성이 저하될 수 있다.12) 즉 분석화학의 영역에서 화학계량학적 접근 혹은 기계학습 모델링의 적용을 결정하기에 앞서 모델 성능 개선을 위한 수단으로서 스펙트럼 데이터 전처리가 시도될 수 있다. 스펙트럼 데이터 전처리는 크게 산란보정(scatter correction)과 스펙트럼 미분(spectral derivatives)으로 대별할 수 있는데 후자의 경우 base line의 보정과 linear trend 제거에 유리하다. 또한 스펙트럼 데이터의 noise 비율을 지나치게 왜곡하는 것을 방지한다.13)
본 연구에서는 닥나무 인피섬유의 원산지 분류를 위한 기계학습 모델링에 있어 스펙트럼 데이터의 전처리 방법이 모델 성능에 미치는 영향을 평가하고자 하였다. 최종적으로 한지의 제조 지역 식별을 통한 보존과학 기술의 전략 수립에 있어 새로운 통찰력과 방향성을 제시하고자 하였다.
2. 재료 및 방법
2.1 공시재료
본 연구에서 사용된 닥 인피섬유 정보를 Table 1에 도시하였다. 증해 과정에 앞서 Table 1의 닥 인피섬유를 기요틴 커터로 절단하였다.
Table 1.
Raw materials for manufacturing Hanji
| Code | Status | M.C., % | Origin |
| W1 | Inner bark | 5.0 | Wonju |
| W2 | 4.1 | ||
| M1 | 4.5 | Imsil | |
| M2 | 4.8 | ||
| M3 | 5.1 | ||
| G1 | 4.8 | Goesan | |
| G2 | 5.8 |
2.2 증해
닥 인피섬유의 증해에는 소다 펄프화법이 사용되었다. 1,000 mL 삼각플라스크에 전건중량 40 g의 공시 재료와 sodium hydroxide (NaOH, powder, 97%, DAEJUNG, Korea)를 전건 섬유 대비 10% 투입하여 autoclave (HST-506-6, Hanbaek, Korea)를 통해 15 psi, 121℃ 조건에서 90분간 가열하였다. 이후 200 mesh wire 상에서 세척과정을 거쳐 적외선 분광분석을 위한 시료로 사용하였다.
2.3 스펙트럼 데이터 수집
증해가 완료된 닥 인피섬유로부터 감쇠 전반사 적외선 분석기 ATR-IR (Alpha-P, Bruker Optics, Germany)를 이용하여 IR 스펙트럼 데이터를 수집하였다. 측정 영역은 4000-400 cm-1 파장범위에 대하여 4 cm-1 간격이었으며, 32회 반복 스캔 데이터의 평균치를 사용하였다. 시료 별 스펙트럼 데이터는 각 10회 반복 측정하여 총 70개의 IR 스펙트럼 데이터 세트를 구성하였다.
2.4 스펙트럼 데이터의 전처리
2.4.1 Savitzky-Golay 알고리즘
Savitzky-Golay 알고리즘에서는 스펙트럼 데이터 segment에 다항식을 적용하여 segment의 중위수에 대한 미분 계수를 취한다.14) 여기서 각 segment는 단계적으로 진행된 convolution 결과를 획득하기 위하여 측정 순서에 따라 이동된다. 본 연구에서는 Savitzky-Golay 알고리즘 의거하여 2차 미분한 스펙트럼 데이터를 데이터 분석 세트로 구성하였다. Savitzky-Golay 알고리즘 데이터 세트 구성 시 스펙트럼 데이터의 2차 미분을 위한 다항식 입력변수는 각각 3차 및 5차로 달리하여 설정하였다.6,10)
2.4.2 Norris-Williams 알고리즘
Norris-Williams 알고리즘에서는 인접한 두 스펙트럼 데이터를 하나의 짧은 직선으로 변형하여 미분하고 해당 미분선을 두 데이터 포인트의 중위점으로 사용한다.15) Norris-Williams 알고리즘 의거한 스펙트럼 데이터의 미분 시 두 가지의 입력변수가 필요하다. 스펙트럼 데이터의 평준화를 위한 파장영역 구간의 길이를 나타내는 segment 변수와 두 segment 사이 구간의 길이를 나타내는 gap이 이에 해당된다. 본 연구에서는 Norris-Williams 알고리즘 의거하여 1차 및 2차 미분한 스펙트럼 데이터를 데이터 분석 세트로 구성하였다. Norris-Williams 알고리즘 데이터 세트 구성 시 1차 미분 및 2차 미분을 위한 segment와 gap은 Rinnan 등16)이 제시한 결과를 참고하여 1차 미분 시 각각 7과 3을, 2차 미분의 경우 9와 3으로 설정하였다. Table 2는 기계학습 모델링을 위한 스펙트럼 데이터의 전처리 정보를 요약한 것이다.
Table 2.
Spectral pre-processing information for machine learning modeling
2.5 다변량 분석 및 기계학습 모델 생성
2.5.1 주성분 분석
수집된 IR 스펙트럼 데이터를 이용하여 닥나무 인피섬유의 원산지에 따른 주요 화학적 성상 변화 추적을 위한 주성분 분석을 진행하였다. 주성분 분석은 고차원 상의 데이터를 새로운 저차원의 직교 좌표계에 사영하는 차원 축소 기법을 통하여 데이터 상의 특정 구조와 패턴을 파악하는데 유용하다고 알려져 있다.5)
2.5.2 데이터 분할
닥나무 인피섬유의 원산지 분류 기계학습 모델링에 앞서 IR 스펙트럼 데이터 세트에 대하여 모델구축에 사용될 훈련용 세트(training set)과 예측력 평가에 사용될 평가용 세트(test set)의 비율을 7:3으로 분할하였다. 데이터 분할에는 계층적 샘플링(stratified random sampling) 방법이 이용되었다. 계층적 샘플링이란 데이터 분할 시 훈련 세트 구성을 위해 추출되는 데이터가 편향적으로 추출될 경우 발생할 수 있는 학습 모델의 일반화 오류를 방지하기 위해 전체 데이터를 계층별 그룹으로 분리하여, 테스트 세트가 전체 데이터 세트의 각 계층의 계수 비율만큼 샘플링 되도록 하는 방법이다.
2.5.3 PLS-DA
PLS-DA는 PLS기법을 이용하여 판별 분석을 수행하는 알고리즘으로 PLS-DA와 PLS는 동일한 분석방법이지만 PLS의 경우는 스펙트럼과 연속형 종속변수를 활용하여 회귀모델로 개발 및 예측하는 반면, PLS-DA의 경우에는 범주형 종속변수를 보유한 자료를 바탕으로 회귀모델을 생성하고 예측한다는 점에 차이가 있다. PLS는 주성분 회귀의 관계를 내포하는 알고리즘으로, 예측되는(predicted) 변수들과 관측되는(observable) 변수들을 새로운 공간으로 사영하여 선형회귀 모델을 생성한다.17)
PLS-DA는 차원 감소와 판별 분석을 하나의 알고리즘으로 결합할 수 있는 방법으로 고차원 독립변수들을 이용한 판별 모델 개발 시 유용하게 사용될 수 있다.5) PLS-DA 구현을 위한 주성분 변수는 초기 15개를 설정한 뒤 최종적으로 격자 검색을 통하여 최적의 성분 변수 개수를 결정하였다.
2.5.4 SVM
SVM은 다차원 공간상에서 두 집단을 분리하는 최적의 초평면(hyperplane)을 탐색하는 모델이다. 두 집단 간의 간격을 최대화하는 초평면을 최대마진초평면(maximal margin hyperplane), 관측값 간의 거리를 마진(margin)이라고 한다. 또한 마진의 경계선상에 있는 점들을 서포트 벡터(support vetor)라고 부른다. SVM은 수학적으로 마진이 최대가 되는 서포트 벡터를 선택하여 그 마진을 이등분하는 지점을 탐색한다.18) SVM 구현 시 초평면은 방사 기저 함수(radial basis function, RBF) 커널을 통해 추정하였으며,19) 오분류에 대한 패널티를 나타내는 cost 인수는 2-5-25으로 설정하고, 데이터를 분할하는 초평면의 형태를 결정하는 gamma 인수에는 10-3-103 범위를 지정하였다. 최종적으로 격자 검색을 통하여 매개변수를 최적화하였다.
2.5.5 KNN
KNN은 데이터로부터 거리가 가까운 k개의 다른 데이터의 레이블을 참조하여 분류하는 알고리즘으로 이때의 거리 측정은 유클라디안 거리 계산법을 이용한다.20) KNN은 판별하고 싶은 데이터와 인접한 k개수의 데이터를 탐색하여 해당 데이터 라벨이 다수인 범주로 데이터를 분류한다. KNN은 구현이 쉽고 기저 데이터 분포에 대한 가정을 하지 않아 훈련속도가 빠르고 효율적인 모델로 알려져 있으나 각 클래스 간의 관계를 이해하는 데 제한적이며 데이터가 많아지면 분류속도가 현저히 떨어진다는 단점이 있다.21) KNN 구현 시 최근접 이웃의 수를 나태내는 매개변수 k는 1, 3, 5, 7로 설정하였으며, 격자 검색을 통하여 최적의 k를 보정하였다.
2.6 모델 성능 검증 및 평가
닥나무 인피섬유의 원산지 분류를 위해 사용된 PLS-DA, SVM, KNN 분류기는 LOO 교차타당법(leave-one-out cross validation, LOOCV)과 격자 검색을 통해 구현되었다. 교차검증 시 전 매개변수에 대한 격자 검색을 진행하여 최종 매개변수를 결정하였다. LOOCV는 교차검증 시 한 개의 데이터만을 남기고 모델을 구축하여 남겨진 한 개를 추정하는 과정을 반복하는 방법이다.22) 이를 통해 상대적으로 적은 양의 데이터 세트 내에서도 우수한 정확도를 갖는 모델을 구현할 수 있다. 그러나 계산량이 광범위하여 모델의 효율성을 저하시킬 수 있다는 단점이 존재한다.
생성된 모델의 평가지표로는 정확도(accuracy), 민감도(sensitivity) 그리고 특이도 (specificity)를 사용하였으며 해당 수식을 Eqs. 1, 2, 3에 나타냈다.
여기서 TP (true positive)는 목표 범주를 정확하게 예측한 것을 의미한다. 즉 예를 들어 A와 B라는 범주를 갖는 데이터가 존재할 때 A 범주를 A로 정확하게 분류하였음을 나타낸다. 반대로 FN (false negative)은 A인 범주를 B라고 예측한 경우로 오분류가 발생하였음을 의미한다. FP (false positive) 역시 B인 범주를 A라고 예측한 경우로 오분류 되었음을 나타낸다. TN (true negative)은 목표변수가 아닌 B 범주를 B로 정확하게 예측한 경우를 의미한다. 본 연구에서 시행된 모든 예측 모델링 작업은 R software (R Core Team, ver. 4.3.0, Auckland, New Zealand)와 오픈 소스라이브러리를 사용하여 수행되었다.
3. 결과 및 고찰
3.1 닥나무 인피섬유의 ATR-IR 스펙트럼
Fig. 1은 닥나무 인피섬유에 대한 IR 스펙트럼 데이터를 도시한 것이다. Fig. 1(a)는 4000-400 cm-1 스펙트럼을 도시한 것이며 Fig. 1(b)는 Fig. 1(a)의 스펙트럼 데이터를 Savitzky-Golay 알고리즘에 의거 5차 다항식으로 2차 미분한 결과를 나타낸다. 닥나무 인피섬유의 경우 비목질계 섬유로서 리그닌이 거의 없고 대부분 셀룰로오스로 구성된 화학적 조성을 보유한다.23)Fig. 1(a)의 원본 스펙트럼 상에서는 3600-3000 cm-1 (OH group)24), 2890-2780 cm-1 (CH stretching), 1422 cm-1 (CH2 bending), 1335 cm-1 (amorphous cellulose), 1200-900 cm-1 (celluloe fingerprint)이 특징적인 흡수 피크로 검출되었다.25,26)Fig. 1(b)에서는 앞서 언급한 파장영역 이외에 1728 cm-1 (C=O stretching)과 1645 cm-1 (OH bending) 피크 정도가 확인되었다.23,25,27) 스펙트럼 전처리 방법에 따른 유효 특성화 피크의 검출 역시 시도하였으나 전처리 방법에 따른 특징 피크의 차이는 미미하였다.
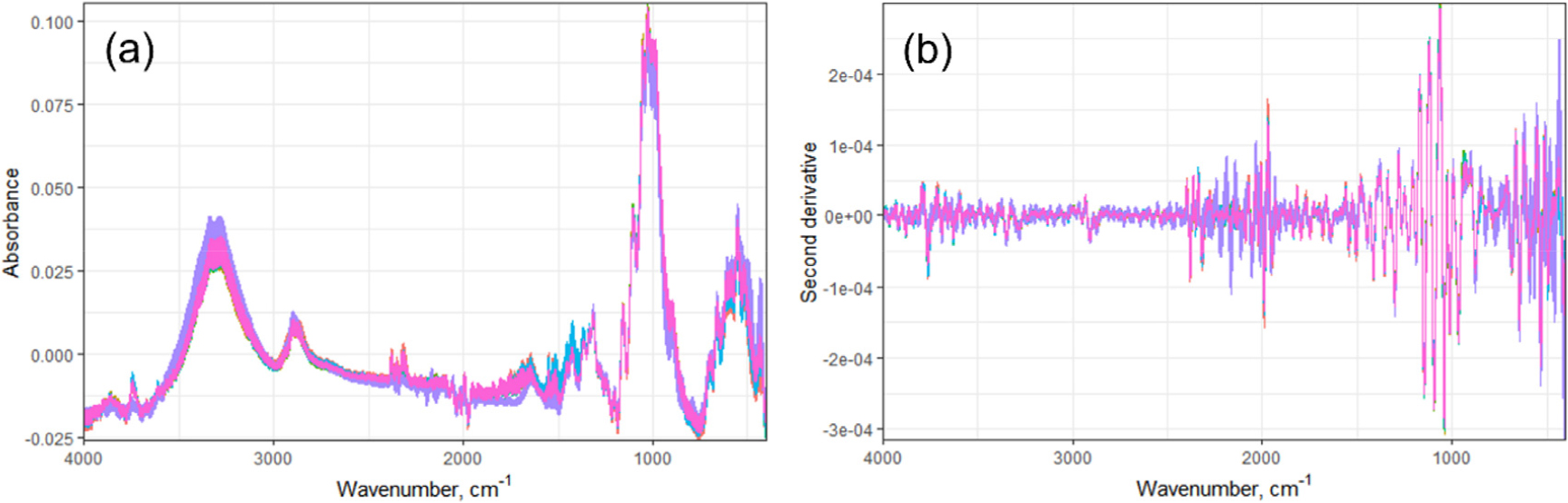
Fig. 2는 스펙트럼 전처리 방법에 따른 스펙트럼 데이터를 도시한 것으로 Table 2에 요약한 조건에 따라 Fig. 1(a)의 원본 스펙트럼을 전처리한 것이다. 알고리즘과 입력변수에 따라 스펙트럼 데이터의 형상이 변화하는 것을 확인할 수 있으며 이에 따라 모델링 시 최종 성능 지표가 변화할 수 있을 것으로 판단된다.
3.2 주성분 분석
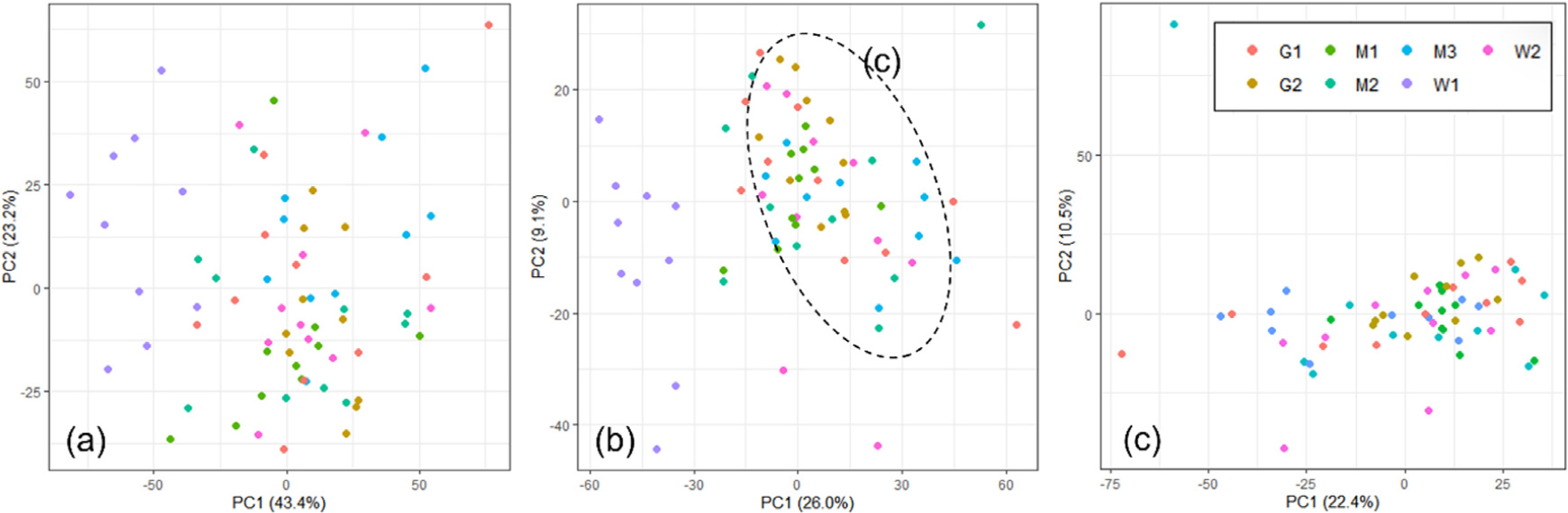
Fig. 3은 Fig. 1의 스펙트럼 데이터로부터 시행한 주성분 분석에 대한 score plot을 도시한 것이다. Fig. 3(a)는 스펙트럼 데이터에 대한 전처리가 진행되지 않은 조건에 대한 PCA score plot을 나타낸 것으로 뚜렷한 클러스터 형성 특징이 나타나지 않을 것을 확인할 수 있다. 반면 Fig. 3(b)의 경우에는 SG2 전처리가 진행된 스펙트럼을 적용한 score plot으로 W1시료가 다른 클러스터로부터 분류되어 나온 것을 확인할 수 있다. 이는 스펙트럼 데이터 전처리의 중요성을 파악할 수 있는 결과이다. Fig. 3(c)는 Fig. 3(b)로부터 분류되지 않은 데이터 세트끼리 주성분 분석을 추가로 진행하여 relocation을 유도한 score plot을 나타낸 것이다. 그러나 Fig. 3(c)에서 확인할 수 있듯이 W1시료 이외에 추가적인 클러스터 형성 특징을 발견할 수는 없었다. 또한 상기의 결과는 스펙트럼 전처리를 달리하였을 때에도 동일한 경향을 나타냈다. 따라서 국내산 닥 인피섬유의 경우 펄프화 공정 혹은 한지 제조 시 첨가되는 첨가제의 영향에 따른 화학적 대별성이 없는 경우 지역에 따른 화학적 이질성을 구별하기에 한계가 있을 것으로 사료된다. Hwang 등10)의 연구에서 국내 전통한지에 대한 제조 지역을 주성분 분석을 통해 성공적으로 분류한 바 있으나 이의 결과는 펄프화 공정과 제조 공정의 차이에 기인하여 나타난 결과로 추정되며, 언급하였듯이 제조 공정에 따른 영향이 포함되지 않은 닥 인피섬유 자체에 대한 분류로서는 다소 무리가 있을 것으로 판단된다.
3.3 PLS-DA
Fig. 4는 스펙트럼 데이터의 전처리 방법에 따른 PLS-DA score plot을 도시한 것이다. PLS-DA는 차원 축소에 있어 독립변수와 종속변수에 대한 공분산을 고려한다는 점에 있어 PCA와 차이를 갖는다. 그러나 각 스펙트럼 전처리 방법이 다르게 적용된 Fig. 4의 PLS-DA score plot 상에서 Fig. 3(b)의 PCA score plot과 명확한 차이를 나타낸 결과는 확인할 수 없었다.
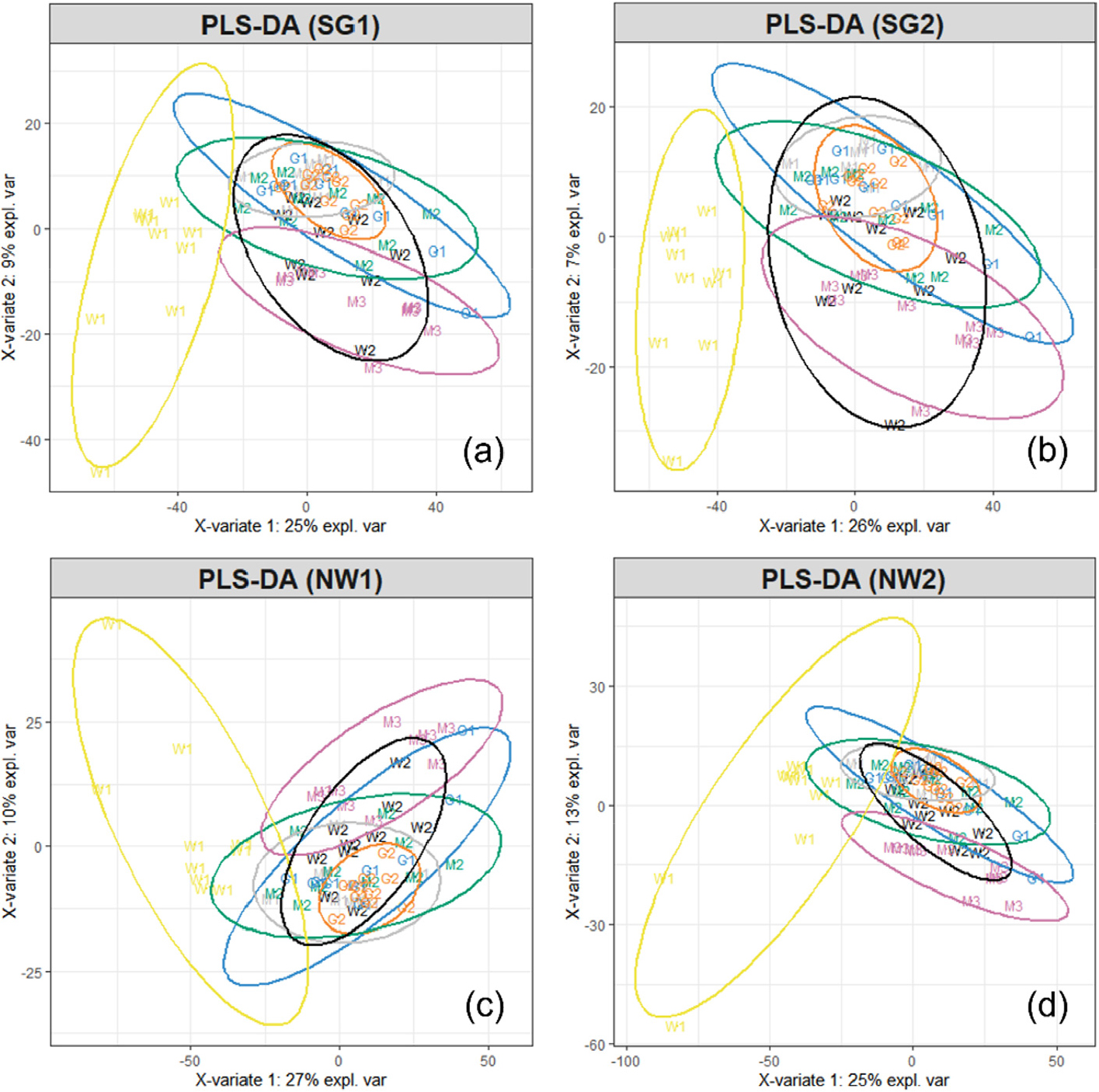
Fig. 5(a)는 Fig. 4에서 시각적 판단을 기준으로 분류 성능이 가장 양호하다고 사료되어진 SG2 전처리를 통해 분석된 PLS-DA score plot 상에서 분류되지 않은 데이터 세트에 대하여 relocation을 유도한 score plot을 나타낸 것이다. Fig. 5(b)는 Fig. 5(a)에 대한 relocation 결과이다. Fig. 5에서 확인할 수 있듯이 우선적으로 분류된 데이터 그룹을 전체 데이터 세트에서 제거함에 따라 모델의 분류성능이 개선되는 것으로 확인되었다. 그러나 Fig. 5(b)를 통해 relocation을 반복 진행하여도 결국 분류되지 않는 데이터 세트 그룹이 나타나는 것을 확인하였다. 이에 스펙트럼 데이터 전처리에 있어 접근 방향을 달리할 필요가 있다고 판단하였다.
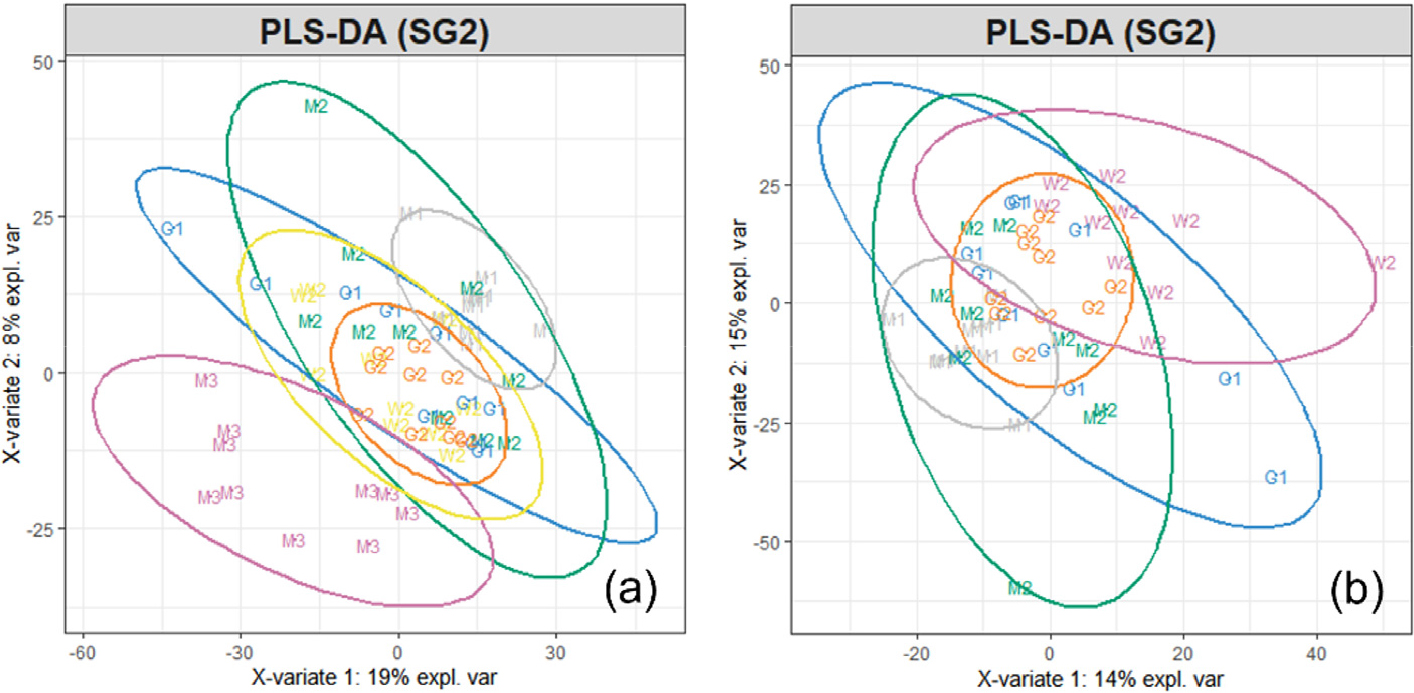
Fig. 5.
PLS-DA score plots based on 2nd derivative IR spectra in 4000-400 cm-1 with SG2 method (a: unclassified in Fig. 4(b); b: unclassified in a).
Fig. 6은 기존의 4000-400 cm-1스펙트럼 영역을 1800-1200 cm-1으로 축소하여 PLS-DA를 수행한 결과를 나타낸 것이다. 1800-1200 cm-1 영역은 Kim 등28)에 의해 종이 화학적 성분에 의한 분류에 있어 유효한 특성화 피크가 다수 관찰되는 영역으로 확인된 바 있다. Hwang 등10)은 분광 스펙트럼을 통한 모델링 과정에서 분류 기능에 도움이 되지 않는 입력 변수를 축소함을 통하여 계산 비용(computational cost)를 효과적으로 감축하고 모델 성능을 개선할 수 있다고 보고하였다.
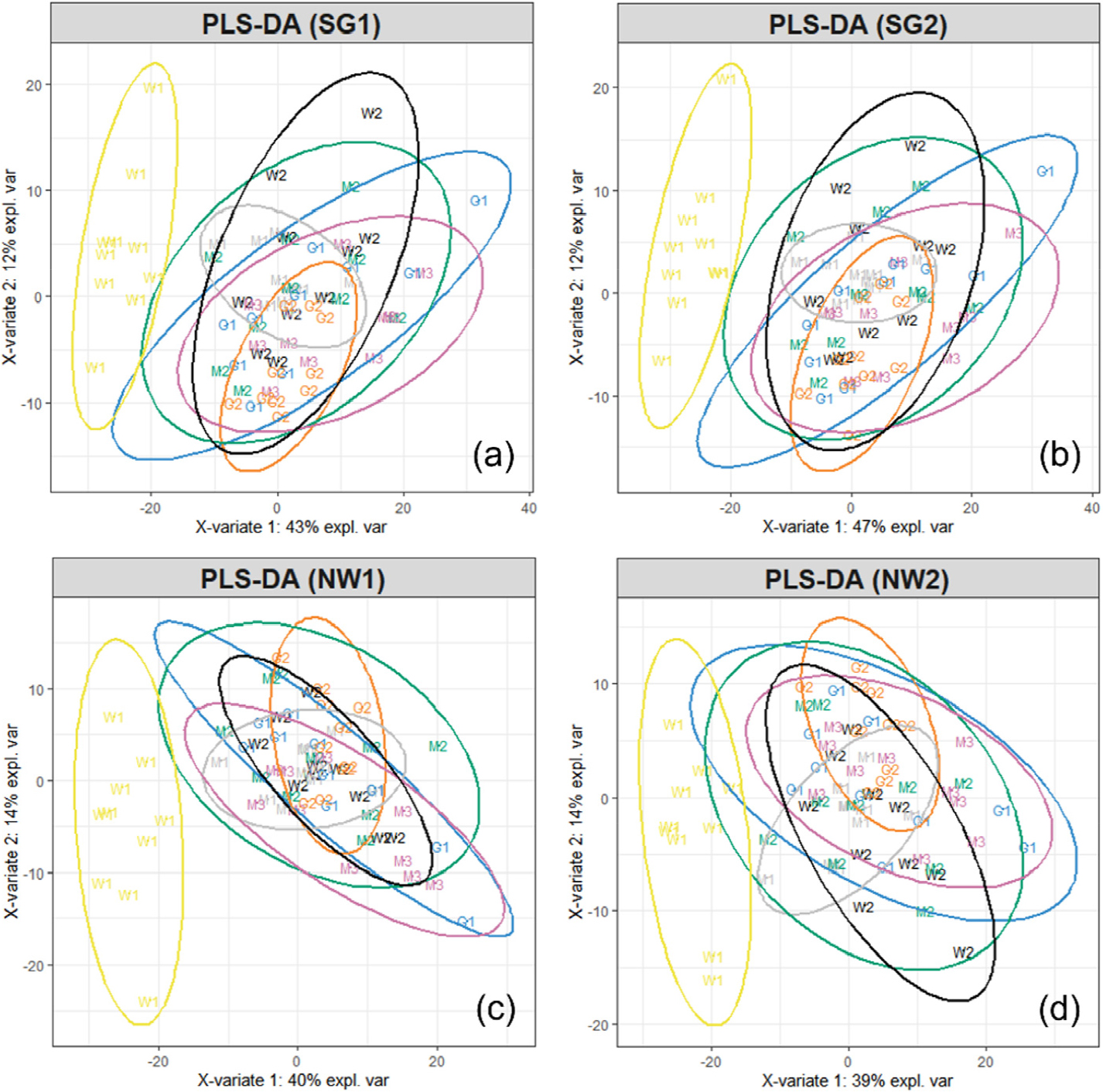
Table 3은 스펙트럼 영역에 따른 PLS-DA의 분류 성능을 도시한 것이다. 예상한대로 스펙트럼 영역을 1800-1200 cm-1 제한하여 모델링한 결과 정확도가 상승하는 결과를 나타냈다. 또한 Figs. 4 및 6에서 2개의 성분 변수를 기준으로 작성된 score plot의 결과와 상반되게 격자검색을 통해 최종 선정된 성분 변수를 적용함에 따라 전처리 방법에 따른 PLS-DA의 분류 성능을 정량적으로 추정할 수 있었다. 전체적인 경향을 보았을 때 PLS-DA 모델에 한하여 닥나무 인피섬유의 원산지 별 분류에 있어 가장 효과적인 IR 스펙트럼 데이터의 전처리 방법은 Norris-Williams 알고리즘에 의한 1차 미분법임 역시 확인 가능하였다.
Fig. 7은 Table 3에서 가장 우수한 분류 성능을 나타냈던 1800-1200 스펙트럼 영역 내 NW1 적용에 따른 스펙트럼 데이터와 PLS loading vector를 나타낸 것이다. PLS 성분은 다양한 변수에 가중치가 부여된 선형조합에 의해 획득되며 loading vector는 이의 영향력 지표를 나타낸다.29)Fig. 7(a)의 스펙트럼 데이터와 Fig. 7(b)의 loading vector를 비교하여 score plot 작성에 대한 논리적 근거를 추정할 수 있다. Fig. 6(c)에서 PC1 축의 경우 데이터 분포에 있어 40%에 해당하는 설명력을 제공하고 있는 것을 확인할 수 있다. 이에 할당된 화학적 성상으로는 크게 결정 셀룰로오스 영역을 나타내는 1315 cm–1 부근 흡수대와30) 1645 cm-1 (OH bending)25,27) 흡수대로 파악되었다. PC2의 경우에는 1660 cm-1 (C=O stretching), 1575-1545 cm-1 (aromatic ring), 1370 cm-1 (C-H bending)과 1226 cm-1 (C-O, C-C, C=O stretching) 등이 해당하는 것으로 분석되었다.25,28) 이와 같이 PLS-DA는 의사결정나무, 랜덤포레스트 등과 더불어 분리 규칙에 대한 논리적 설명을 제공한다.
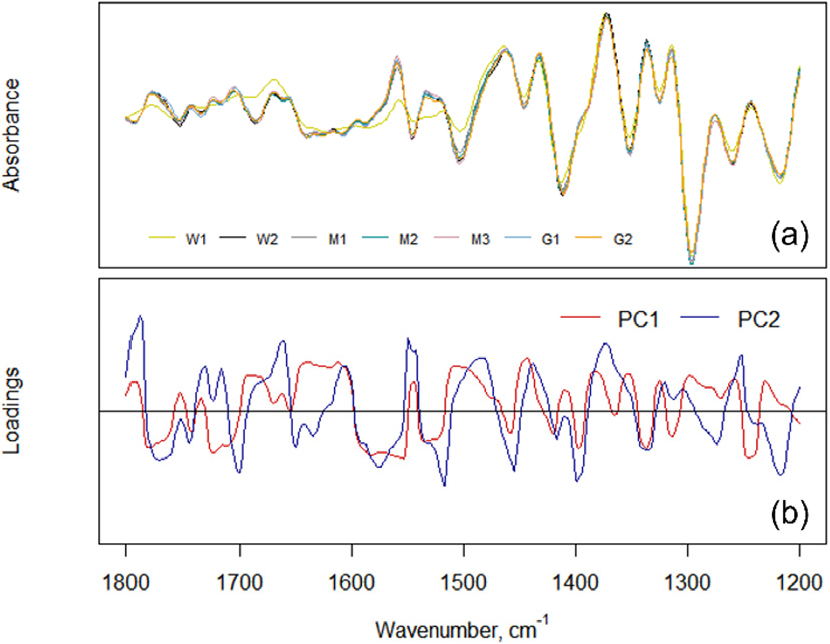
Fig. 7.
PLS loading vectors in the range of 1800-1200 cm-1 for PLS-DA score plot of Fig. 6(c) (a: first derivative IR spectra with NW1; b: PLS loading vectors).
Table 3.
Classification performance of PLS-DA model with respect to wavenumber region
| Wavenumber, cm-1 | Pre-processing | Accuracy | |
| Train | Test | ||
| 4000-400 | SG1 | 0.633 | 0.571 |
| SG2 | 0.592 | 0.524 | |
| NW1 | 0.816 | 0.667 | |
| NW2 | 0.816 | 0.619 | |
| 1800-800 | SG1 | 0.653 | 0.762 |
| SG2 | 0.490 | 0.667 | |
| NW1 | 0.816 | 0.905 | |
| NW2 | 0.673 | 0.905 | |
3.4 분류모델의 성능 비교
일반적으로 데이터 분석 및 평가에 사용되는 알고리즘은 비지도 학습과 지도학습으로 대별된다. 비지도 학습의 경우 데이터의 유사성에 근거하여 데이터 상의 숨겨진 패턴과 구조를 탐색하는 방법인 반면 지도 학습의 경우 사전에 정의된 범주형 변수를 통하여 새로운 입력 변수에 대한 분류 결과를 제시함으로써 성능평가에 의한 평가지표를 보고한다.31)
Table 4.
Accuracy of classification models trained with the spectral range of 1800-1200 cm-1
Table 4는 기계 학습 분류기에 따른 모델의 분류 정확도를 도시한 것이다. Table 4의 모델링에 따른 분류 성능은 1800-1200 cm-1 영역의 데이터 세트에 한하여 평가되었다. 앞서 PLS-DA 결과와 마찬가지로 스펙트럼 데이터의 전처리 방법에 따른 분류 성능에 있어서는 NW1의 적용이 전체 모델 내에서 가장 우수한 성능을 부여할 수 있는 것으로 분석되었다. 분류모델에 따른 차이에 있어서는 KNN이 전반적으로 타 분류기에 비하여 상대적으로 낮은 성능을 나타낸 것을 확인할 수 있다. 이는 KNN이 유클리드 거리를 근거하여 인접한 데이터에 대한 분류를 수행하는 비교적 간단한 모델임에 기인한 결과로 해석된다. PLS-DA의 경우 격자 검색을 통해 선정된 최적 성분수는 11-13인 것을 확인할 수 있었다. 또한 제곱근 평균 제곱 예측오차(root mean square error of prediction, RMSEP)의 계산을 통한 이상적인 주성분 수의 검토결과 주성분 수 조정을 통한 모델 튜닝의 여지는 남아있지 않은 것으로 판단할 수 있었다. 한편 SVM의 경우 본래 PLS-DA와 같은 선형 모델이지만 커널 트릭을 적용하여 데이터를 고차원 특징 공간으로 투영함을 통해 비선형 분류를 수행할 수 있도록 모델링 하였다. 따라서 PLS-DA에 비하여 우수한 분류 성능을 보유할 것으로 예상하였으나 결과는 이와 상반되었다. 이는 SVM의 경우 cost 인수와 gamma 인수에 대한 튜닝 여지가 남아있음에 따른 결과로 해석할 수 있다. 데이터를 분할하는 초평면의 형태를 결정하는 gamma 인수의 경우 높게 설정할수록 tortuous 형태의 초평면이 생성됨에 따라 비선형 분류에 있어 유리해진다. 그러나 cost 인수와 gamma 인수를 높게 설정할 경우 계산 비용과 과적합(overfitting)의 가능성이 증가된다. 따라서 데이터 세트에 따라 상호보완적 입력변수의 설정이 요구되며 적절한 튜닝을 통하여 분류 성능을 최적화할 필요가 있다. SVM의 경우 다양한 상황에서 비교적 우수한 예측성능을 보이는 것으로 알려져 있으나 PLS-DA, 의사결정나무 및 랜덤포레스트 등과는 다르게 분류규칙에 대한 논리적 설명은 어렵다는 단점을 갖는다.
3.5 분류모델의 성능지표
분류모델이 한 방향으로 치우치면 올바를 예측을 할 수 없으므로 너무 공격적이지도 않고 지나치게 보수적이지도 않은 균형 있는 예측 성능을 보유할 필요가 있다. 예측모델의 민감도는 실제 positive 케이스 중 모델에 의해 실제로 positive 케이스로 올바르게 분류한 비율로 측정한다. 반대로 특이도는 negative 케이스 중 모델에 의해 실제로 negative 케이스로 올바르게 분류한 비율을 나타낸다. 민감도와 특이도는 서로 트레이드오프(trade-off) 관계를 갖기에 두 지표간 적절한 균형점을 설정하는 것이 중요하다. Table 5는 1800-1200 cm1 영역 내의 스펙트럼 데이터를 NW1에 의거 전처리한 데이터 세트로 모델링한 분류모델의 정확도, 민감도 및 특이도를 요약한 것이다. 일반적으로 요구되는 민감도와 특이도를 충족하는 모델을 찾을 때까지 예측모델을 수정하고 테스트하는 작업이 반복된다. 민감도와 특이도 지표 역시 앞서 확인한 정확도 지표의 경향과 유사하게 KNN이 상대적으로 낮은 수치를 기록한 것을 확인할 수 있다.
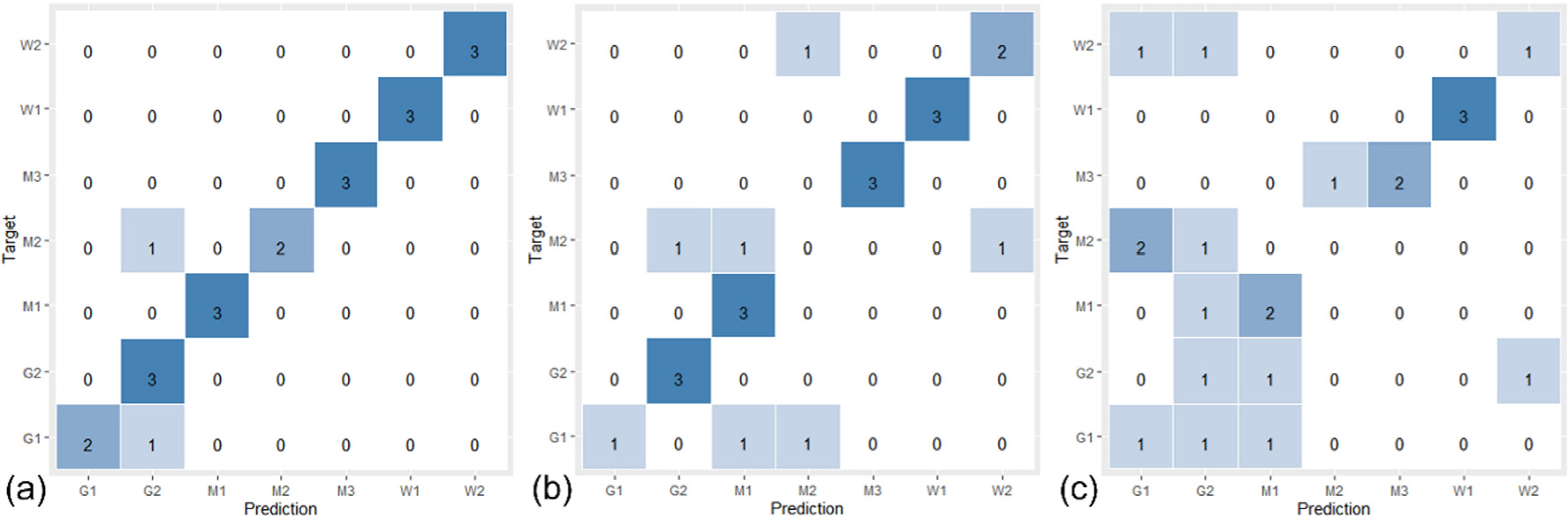
Fig. 8은 1800-1200 cm1 영역 내의 스펙트럼 데이터를 NW1에 의거 전처리한 데이터 세트로 모델링한 분류모델의 혼동 행렬을 나타낸 것으로 실제 범주와 예측 범주 가운데 분류 및 오분류 케이스에 대한 정보를 확인할 수 있다. Fig. 8(a) PLS-DA와 Fig. 8(b) SVM에서 발생한 오분류 케이스를 살펴보면 대부분 동일 지역내 시료에 대한 오분류가 발생하는 사실을 파악할 수 있는 반면 Fig. 8(c) KNN의 경우 오분류 케이스가 지역에 관계없이 랜덤하게 발생하고 있는 것으로 확인할 수 있다. 따라서 모든 성능 지표를 종합적으로 고려하였을 때 KNN 보다는 계산 복잡도가 다소 높은 모델이 닥나무 인피섬유의 원산지 분류 모델로서 검토되어야 한다고 사료된다.
Table 5.
Performances of the classification models trained by IR spectra pre-processed with NW1 method in the spectral range of 1800-1200 cm-1
| Code | PLS-DA | SVM | KNN | ||||||
| Acc. | Sen. | Spe. | Acc. | Sen. | Spe. | Acc. | Sen. | Spe. | |
| W1 | 0.905 | 1.000 | 1.000 | 0.810 | 1.000 | 1.000 | 0.571 | 1.000 | 1.000 |
| W2 | 1.000 | 1.000 | 0.667 | 0.944 | 0.333 | 0.944 | |||
| M1 | 1.000 | 1.000 | 1.000 | 0.889 | 0.667 | 0.889 | |||
| M2 | 0.667 | 1.000 | 0.000 | 0.889 | 0.000 | 0.944 | |||
| M3 | 1.000 | 1.000 | 1.000 | 1.000 | 0.667 | 1.000 | |||
| G1 | 0.667 | 1.000 | 0.333 | 1.000 | 0.333 | 0.833 | |||
| G2 | 1.000 | 0.889 | 1.000 | 0.944 | 0.333 | 0.778 | |||
4. 결 론
본 연구에서는 한지 제조 지역 분류를 위한 기계 학습 모델링 시 스펙트럼 전처리에 따른 영향을 확인하였다. 먼저 주성분 분석 시행 결과 주성분 분석의 반복 시행에 따른 클러스터의 relocation을 유도할 수 있었으나 시행 횟수가 증가함에 따라 제한적인 결과가 나타나는 것을 확인하였다. 지도 학습 모델인 PLS-DA에서 역시 비슷한 경향이 확인되었다. 스펙트럼 전처리 방법에 따라 모델 성능을 개선할 수 있는 여지가 존재함을 확인하였으며 특히 선택적 스펙트럼 영역(1800-1200 cm-1)의 적용은 분류 모델의 성능향상을 위한 효과적 전략이라 판단된다. 분류 모델 별 성능의 경우 KNN이 가장 낮은 정확도를 보유함이 확인되었으며 PLS-DA와 SVM의 경우 상대적으로 우수한 정확도를 나타냈다. 종합적인 성능 지표를 참고하였을 때 KNN 보다는 계산 복잡도가 다소 높은 모델이 한지의 기계학습 분류 모델로서 고려되어야 한다고 사료된다. 추가적으로 Norris-Williams 알고리즘 의거한 1차 미분 스펙트럼 전처리는 본 데이터 세트의 동일 분류기 내에서 모델 성능을 개선할 수 있는 효과적 접근법임을 확인할 수 있었다. 이상의 결론을 통해 한지의 제조 지역 분류에 있어 적외선 스펙트럼 데이터 전처리와 기계학습 모델링의 적용 가능성은 전도유망하다고 판단할 수 있었으며 단순 분류를 넘어 분류 규칙에 대한 논리적 근거를 통하여 화학적 성상에 대한 추적도 가능할 것이라 사료된다.
