

1. 서 론
2. 재료 및 방법
2.1 재료
2.2 데이터 세트
2.3 주성분 분석
2.4 계층적 군집분석
2.5 분류 모델 수립
3. 결과 및 고찰
3.1 적외선 분광학적 특성
3.2 주성분 분석
3.3 계층적 군집분석
3.4 분류 모델 평가
3.5 분류 성능 비교
3.6 한지의 지역적 특성에 대한 고찰
4. 결 론
1. 서 론
우리나라의 전통 종이 한지는 오늘날에도 여전히 가치와 기술이 살아있는 우리 민족의 고유한 문화유산이다. ‘비단은 오백 년을 가지만, 한지는 천년을 간다’라는 뜻인 ‘견오백지천년(絹五百紙千年)’은 한지와 우리의 종이 문화의 우수성을 상징하는 말이다. 1966년 경주 불국사 석가탑 해체 과정에서 발견되어 국보 제126호로 지정된 ‘무구정광대다라니경’은 1200년이 넘는 세월을 버텨낸 우수한 한지의 보존성과 선조들의 제지 기술을 보여주는 대표적인 사례이다. 최근 전 세계의 보존 전문가들은 한지의 강한 내구성에 주목하여 한지를 보존 및 보수 재료로서 채택하고 있다.1)
국가지정문화재(국보 및 보물) 2,705건 중 종이문화재는 826건으로 30.5%의 가장 큰 비중을 차지한다.2) 그러나 한지는 우수한 내구성을 가졌음에도 불구하고 유기물이라는 특성상 시간의 흐름에 취약하므로 이를 취급하기 위해서는 고도의 기술과 지식이 요구된다. 특히, 국보와 보물로 지정된 중요 문화재의 경우 분석을 위한 시료 채취가 원천적으로 불가능하기에 비파괴적 방식의 분석만이 제한적으로 허용된다.
특정 파장의 빛과 물질의 상호작용을 통해 재료의 특성을 조사하는 분광 분석은 재료의 영구적인 변화를 일으키지 않고 특성화하는 대표적인 비파괴적 방법이다. 적외선(infrared, IR)과 근적외선(near-infrared, NIR) 분광법은 다양한 재료의 특성 평가를 위한 비파괴적 접근 방식으로 널리 사용되고 있다.3,4,5) 종이를 비롯한 목질계 소재의 정보 획득과 분석에서도 분광법은 매우 유용하며, 분석 도구로는 주로 통계적 다변량 분석 기법이 활용되고 있다.6,7,8,9,10) Kang 등(2021)11)과 Kim 등(2022)12)은 IR 분광법과 주성분 분석을 이용하여 복사지의 분류 가능성을 확인하였으며, Kim과 Eom(2016)13)은 지종 분류에 대한 IR과 NIR 분광법의 차이를 조사하였다. 이러한 접근 방식은 종이의 열화 특성 분석에서도 유효함이 확인되었다.14)
다변량 분석은 분광법과 결합하여 다양한 분석 시나리오에서 사용되었고 가치를 인정받았지만 예측 모델링을 위한 도구로서는 몇 가지 한계를 가지고 있다. 다변량 분석은 변수 간의 선형 관계를 가정하는 경우가 많은데, 이러한 가정은 비선형적이거나 변수 간의 상호작용이 복잡한 데이터에서는 적용되지 않을 수 있다.15) 그리고 다변량 분석은 고차원 데이터 세트, 특히 관측값보다 변수의 수가 많은 상황에서 과적합 또는 계산 복잡성의 증가와 같은 문제에 직면한다.16) 이러한 제한 사항들은 예측 모델의 유연성과 확장성을 저해하는 요인이다.
기계학습은 다변량 분석의 한계를 보완할 수 있는 유망한 기법이다. 기계학습 알고리즘은 기존의 다변량 분석보다 변수 간의 비선형적이고 복잡한 관계를 더욱 효과적으로 포착할 수 있다.17)또한, 기계학습 알고리즘, 특히 심층학습 및 신경망 기반의 알고리즘은 대규모 데이터 세트를 효율적으로 처리하며, 불완전 데이터에 대해 견고한 특성을 가진다. 예측 모델링에 있어 기계학습은 변화하는 데이터 패턴에 따라 예측을 갱신할 수 있기에 변수 간의 관계가 변할 수 있는 동적 환경에 적합하다.17)
기계학습은 예측 모델링을 위한 강력한 도구이지만, 다변량 분석의 효용성을 완전히 대체하는 것은 아니다. 그러므로 데이터의 특성 및 연구 목적에 따라 적절한 방법을 선택하는 것이 중요하다. 다변량 분석 기법인 부분 최소제곱 회귀를 이용한 바이오매스의 수분 예측 모델링에서 기계학습 기법인 밀도 기반 클러스터링(density-based spatial clustering of applications with noise)을 적용하여 이상치를 탐지한 사례18)와 NIR 스펙트럼 데이터를 이용한 탄화 특성 예측에서 의사결정트리 알고리즘을 이용한 중요 스펙트럼 영역을 식별한 사례19)와 같이 기계학습과 다변량 분석은 상호 보완적으로 사용되고 있다. 다양한 소재의 예측 모델링에 기계학습이 활발히 적용되고 있음에도 불구하고 한지를 비롯한 종이 소재 연구에 대한 기계학습 기법의 활용은 미미한 실정이다.
본 연구에서는 기계학습을 이용한 한지의 특성 예측 연구의 하나로 인공신경망과 IR 분광법을 이용하여 한지의 제조 지역 판별 가능성을 조사하였다. IR 스펙트럼으로부터 한지의 특성을 추출하고 인공신경망 분류기를 적용하여 한지의 제조 지역을 분류하였다. 한지와 같은 전통 종이는 제조 지역에 따라 섬유 구성 및 화학적 특성이 뚜렷하다. 따라서 한지의 제조 지역 식별은 고문서, 예술품, 문화재로부터 새로운 통찰력을 발견하는 데 이바지할 수 있으며, 종이문화재의 보존 및 복원에 적합한 재료를 선택하는 데 있어 데이터에 입각한 결정을 내리는 데 도움을 줄 수 있다.
2. 재료 및 방법
2.1 재료
본 연구에서는 안동, 가평, 경주, 문경에서 닥나무(Broussonetia kazinoki)의 인피섬유로 제조된 한지 4종과 전통 방식으로 제조한 인피섬유로 만든 수초 한지 1종을 실험에 사용하였다. 수초 한지의 상세한 제조방식은 Jeong 등(2014)20)의 연구 논문에서 확인할 수 있다. Table 1에 제시된 바와 같이 본 연구에 사용된 한지의 특성은 제조 지역에 따라 차이를 나타내었는데, 이는 한지의 제조방식과 용도 차이에 기인한다. 안동과 경주 한지에서는 증해 약품으로 수산화나트륨이 사용되었고, 가평, 문경, 수초 한지에는 천연 잿물이 사용되었다. 그리고 모든 한지는 분산제로 황촉규근의 점액(닥풀)을 사용하여 제작되었다.
Table 1.
Manufacturing origins and characteristics of Hanji20)
2.2 데이터 세트
2.2.1 적외선 스펙트럼 획득
감쇠 전반사 적외선 분광기(attenuated total reflection infrared spectroscopy, ATR-IR; Alpha-P model, Bruker Optics, Germany)를 이용하여 한지 시료로부터 4000-400 cm-1 파장 범위의 IR 스펙트럼을 획득하였다. 분광기의 분해능은 4 cm-1이며, 16회 반복 스캔의 평균 스펙트럼이 획득되었다. 지역별 한지 및 수초 한지 시료로부터 10개의 스펙트럼이 획득되어 데이터 세트는 총 50개의 IR 스펙트럼으로 구성되었다.
2.2.2 데이터 전처리
획득된 한지의 IR 스펙트럼은 Savitzky-Golay 필터21)에 의해 전처리되었다. 원본 스펙트럼은 평활화 필터링과 3차 다항식을 통해 2차 미분 스펙트럼으로 변환되었다. Savitzky-Golay 필터를 이용한 데이터 전처리는 스펙트럼의 베이스라인을 일정하게 조정하고 피크를 증폭하여 시료 간 차이를 강조하는 효과가 있다.6)
분광 스펙트럼에는 분류에 있어 도움이 되지 않는 노이즈와 정보가 다수 포함되어 있다. 이러한 과도한 수의 입력 변수(스펙트럼)는 계산 비용(computational cost)을 증가시키는 주요 원인이 된다. 한지 시료로부터 획득된 4000-400 cm-1 영역의 IR 스펙트럼은 2,545개의 입력 변수를 가진다. 따라서 본 연구에서는 IR 스펙트럼 데이터를 4000-400 cm-1과 1800-1200 cm-1의 두 영역으로 나누어 각각의 데이터 세트를 생성하여 분류에 사용하였다. 1800-1200 cm-1 영역은 Kim과 Eom(2016)14)에 의해 종이의 특성화에 적합한 스펙트럼 범위임이 확인되었으며, 이 영역은 425개의 입력 변수에 해당한다.
2.2.3 데이터 분할
데이트 세트를 7:3의 비율로 훈련 세트와 테스트 세트로 분리하여 분류 모델 수립 및 평가에 사용하였다. 데이터 분할에는 층화추출법(stratified random sampling)을 사용하였고 이 방법은 모든 클래스(생산 지역)에 대해 7:3의 분할 비율을 보존한다.
2.3 주성분 분석
지역별 한지의 IR 스펙트럼 데이터 분석을 위해 주성분 분석(principal component analysis, PCA)을 수행하였다. PCA를 통해 4000-400 cm-1과 1800-1200 cm-1 영역의 고차원 IR 데이터를 6개의 주성분(principal component, PC)으로 구성된 새로운 직교 좌표계로 변환하였다. 변환된 데이터를 저차원 공간에 시각화하여 지역별 한지의 IR 데이터에 존재하는 구조와 패턴을 분석하였다.
2.4 계층적 군집분석
한지의 생산 지역 간 수치적 거리 기반의 관계를 알아보기 위해 비지도 학습 기반의 응집형 계층적 군집분석(agglomerative hierarchical clustering)22)을 수행하였다. 데이터 포인트 간의 유클리디언 거리(Euclidean distance)의 오차 제곱 합의 증가에 기반하여 군집을 형성하는 Ward 연결법(Ward linkage method)23)을 사용하였다. 군집은 덴드로그램(dendrogram)으로 표현되었고 생성된 덴드로그램이 실제 데이터 포인트 간 쌍별 비유사도(pairwise dissimilarity)의 보존 정도를 파악하기 위해 코페네틱 상관계수(cophenetic correlation coefficient)24)를 산출하였다. 코페네틱 상관계수는 –1에서 1의 범위를 가지며, 1에 가까울수록 덴드로그램이 데이터 포인트 간의 실제 거리를 정확하게 나타낸다는 것을 의미한다.
2.5 분류 모델 수립
2.5.1 인공신경망
한지의 제조 지역 판별을 위해 인공신경망(artificial neural networks) 분류기를 사용하였다. 분류기로는 역전파(backpropagation) 기능을 갖춘 다층 피드 포워드 신경망(feed-forward neural network, FNN)이 사용되었다. FNN 분류기는 훈련 세트의 IR 스펙트럼을 학습하였으며, 분류 모델 구축을 위한 활성화 함수 및 손실함수로서 정류 선형 유닛(rectified linear unit, ReLU)과 교차 엔트로피(cross entropy)가 각각 사용되었다. 모델의 손실함수 최적화를 위해 확률적 경사 하강법(stochastic gradient descent) 기반의 SGD와 Adam을 각각 사용하였다. 초기 학습률은 0.0001, 0.001, 0.01, 0.1의 범위가 적용되었고 최대 반복 횟수는 3000번으로 설정하였다. FNN의 은닉층(hidden layer)은 1개 또는 2개로 설계하였고, 각 은닉층은 100, 500, 1000, 2000개의 노드로 구성하였다. 격자 검색(grid searching)을 통해 분류를 위한 모델의 최적 매개변수와 네트워크 구조가 선정되었다.
2.5.2 k-최근접 이웃 알고리즘과 서포트 벡터 머신
FNN 모델의 분류 성능을 평가하기 위해 k-최근접 이웃(k-nearest neighbor, KNN) 알고리즘과 서포트 벡터 머신(support vector machine, SVM) 기반의 분류 모델을 각각 구축하여 성능을 비교하였다.
최소 거리 기반 알고리즘인 KNN은 훈련 데이터를 학습하지 않고 입력된 테스트 데이터와 훈련 데이터 사이의 거리를 계산하여 가장 가까운 훈련 데이터의 클래스로 테스트 데이터를 할당한다. KNN 알고리즘의 매개변수인 최근접 이웃의 수 k는 1, 3, 5, 7로 설정하였으며, 격자 검색을 통해 최적의 k를 결정하였다.
SVM은 클래스 간의 최대 폭 결정 경계를 찾아 선형 분류하는 알고리즘이다. 분류에는 데이터를 고차원 공간에 투영하여 초평면(hyperplane)을 결정하는 방사 기저 함수(radial basis function, RBF) 커널을 사용하였다.25) RBF 커널 SVM 모델 구축에서 훈련 데이터의 오분류 비용에 대한 매개변수인 cost는 100~105로 설정하였고, 비선형 분류를 위한 Gaussian 커널을 제어하는 매개변수인 gamma는 10-1~10-6의 범위로 설정하였다. 격자 검색을 통해 매개변수를 최적화하였다.
2.5.3 모델 검증 및 매개변수 최적화
한지의 생산지 분류를 위해 사용된 FNN, KNN, SVM 분류기는 k-겹 교차검증(k-fold cross validation)과 격자 검색을 통해 수립되었다. 3겹 교차검증을 수행하여 모델의 오차를 산출하였고, 교차검증 과정에서 모든 매개변수에 대한 격자 검색을 수행하여 모델별 최적 매개변수를 결정하였다. 최적 모델은 최소 오차를 기반으로 선정하였고 테스트 세트에 대한 분류 모델의 성능은 정확도(accuracy)로 평가하였다. 본 연구에서 시행한 모든 분석 및 예측 모델링 작업은 Python 3.9와 오픈 소스 라이브러리를 사용하여 수행되었다.
3. 결과 및 고찰
3.1 적외선 분광학적 특성
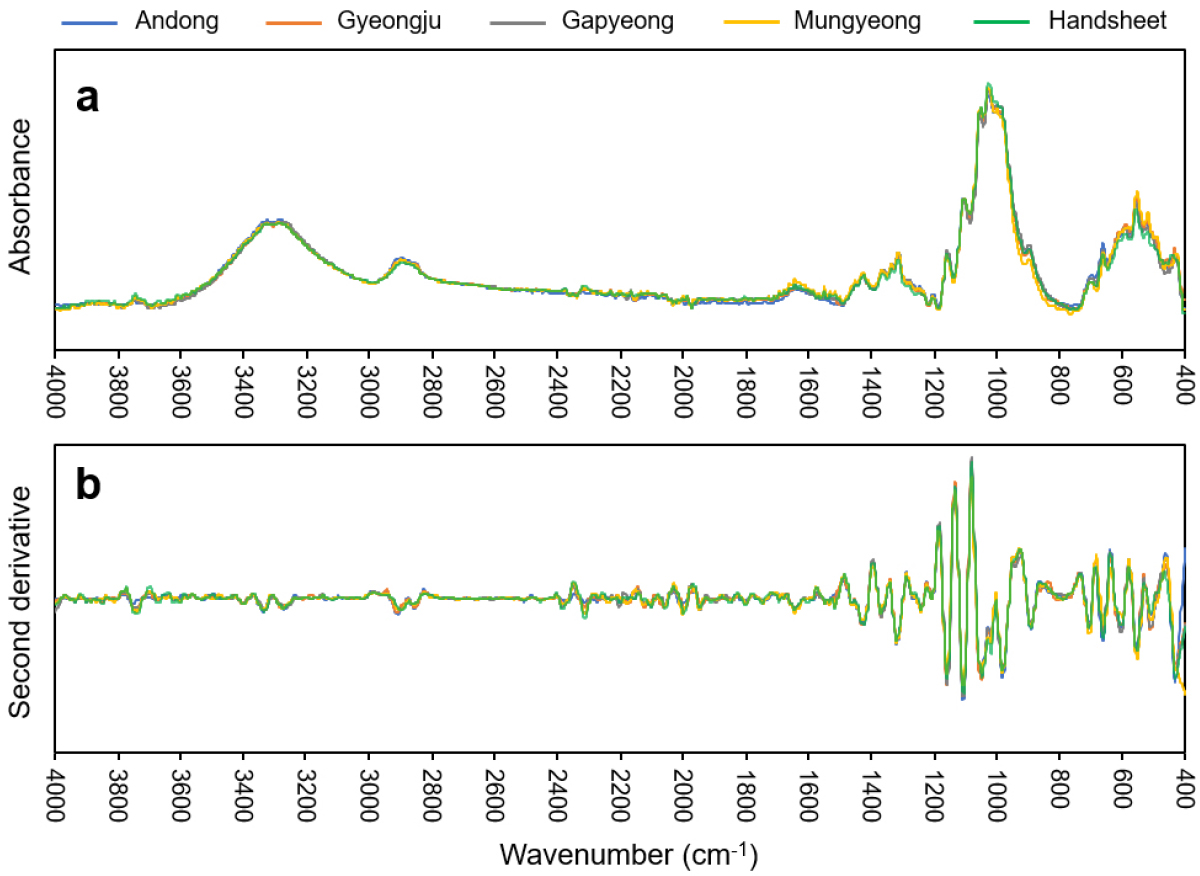
한지의 IR 스펙트럼은 화학 성분과 구조에 대한 정보를 제공한다. Fig. 1는 4000-400 cm-1의 전체 스펙트럼 영역에서 한지 시료의 IR 스펙트럼(Fig. 1a)과 2차 미분 스펙트럼(Fig. 1b)을 보여준다. Fig. 1a의 원본 IR 스펙트럼에서 3600-3000 cm-1(OH group)26), 2890-2780 cm-1(CH stretching)27), 1647-1635 cm-1(water)28), 1422 cm-1(CH2 bending)29), 1335 cm-1(amorphous cellulose)30), 1200-900 cm-1(cellulose fingerprint)31)이 특징적인 흡수대였다.
2차 미분 스펙트럼(Fig. 1b)은 원본 스펙트럼에 포함된 많은 노이즈로 인해 매끄럽지 않은 형상을 나타냈다. 특히 4000-1800 cm-1 영역은 증폭된 노이즈가 지배적이었다. 노이즈를 제어하기 위해 2차 미분 변환 과정에서 평활화 필터를 적용하였다. 평활화 필터가 커질수록 노이즈는 감소하지만 이와 더불어 약한 강도의 스펙트럼 피크가 소실될 우려가 있다. 이러한 사항을 고려하여 적정 수준(21 point)의 평활화 필터 크기를 결정했으나 노이즈는 충분히 정제되지 않았다. 2차 미분 스펙트럼에서는 원본 스펙트럼에서 언급된 특징적 피크를 제외하고 1510 cm-1(aromatic ring)32), 1315 cm-1(crystalline cellulose)33)의 흡수대가 두드러졌다.
3.2 주성분 분석
PCA는 고차원 데이터 세트에서 의미 있는 패턴과 구조를 추출하고 분석하는 데 사용되는 차원 축소 기법이다. Fig. 2의 스코어 플롯은 고차원 IR 스펙트럼으로부터 변환된 PC 중 최대 분산을 나타내는 PC1과 PC2를 이용한 한지 데이터의 2차원 시각화를 보여준다.
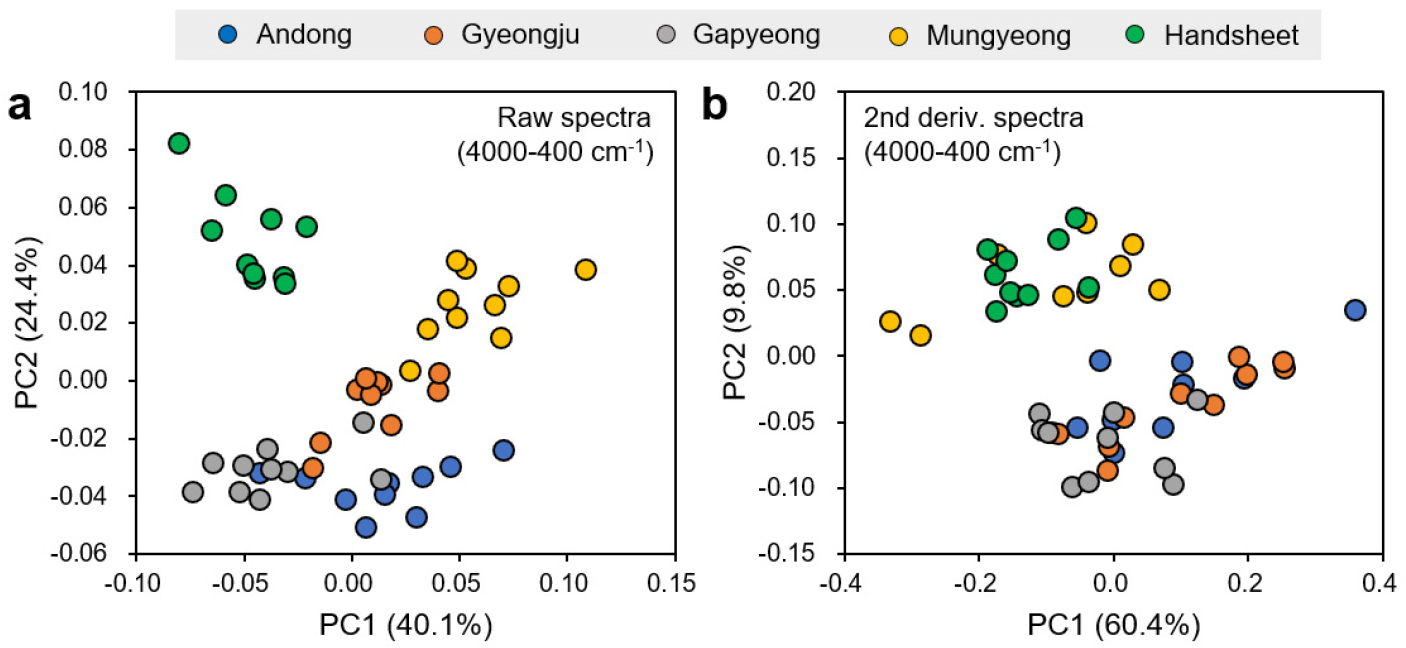
Fig. 2a의 전체 영역(4000-400 cm-1)에 해당하는 원본 스펙트럼으로부터 생성된 스코어 플롯에서는 데이터 포인트들이 한지 제조 지역별로 어느 정도의 군집을 형성하였다. 특히 수초 한지의 경우 다른 지역들과 명확히 구분되는 영역에 독립적인 군집을 형성하였다. 이는 증해 과정에서 사용된 잿물의 종류(NaOH, K2CO3)와 초지 환경의 차이에 기인하는 것으로 보인다.
Fig. 2b의 2차 미분 IR 스펙트럼 기반 스코어 플롯에서는 명확한 두 개의 군집이 형성되었다. 하나의 군집은 수초 한지 및 문경 한지로 구성되었고, 다른 군집은 안동, 경주, 가평 한지로 구성되었다. 스펙트럼 전처리를 통해 군집들 간의 차이는 명확해졌으나 제조 지역별 구분은 사라졌다. 이러한 결과는 스펙트럼의 2차 미분 전처리가 한지의 제조 지역 분류를 위한 좋은 접근 방식이 아님을 보여준다. 2차 미분 전처리 후 제조 지역별 군집이 불명확해진 것은 4000-1800 cm-1 영역에 존재하는 다수의 노이즈에 의한 영향인 것으로 판단된다. 이러한 불필요한 신호들이 2차 미분으로 증폭되어 오히려 지역별 구분을 어렵게 만든 것으로 판단된다.
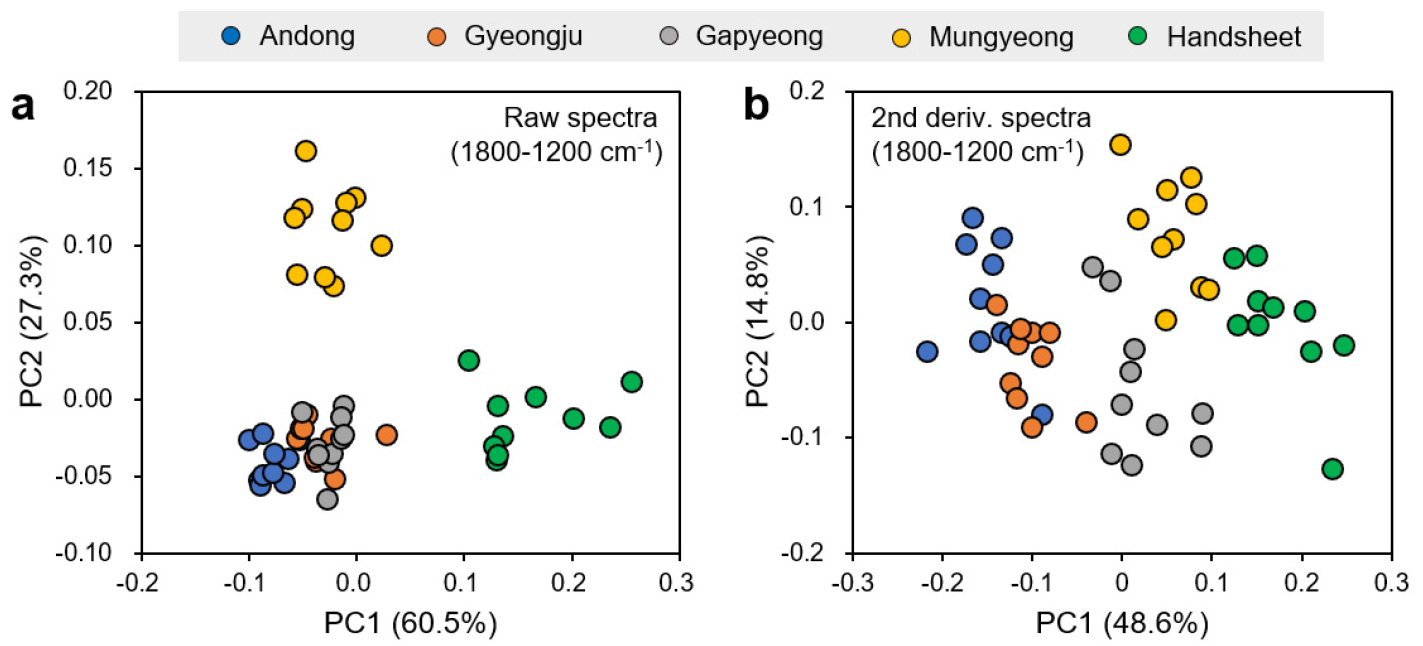
종이의 특성화에 적합한 스펙트럼 영역으로 선택된 1800-1200 cm-1 영역의 스펙트럼 기반 스코어 플롯은 다소 다른 양상을 나타냈다(Fig. 3). Fig. 3a의 원본 스펙트럼 기반 스코어 플롯에서는 수초 한지 및 문경 한지가 각각 PC1과 PC2를 기준으로 다른 지역들과 명확히 구분되는 영역에 위치하였다. Fig. 4에는 1800-1200 cm-1 영역의 IR 스펙트럼과 그에 대응하는 PC 로딩값이 제시되어 있다. PC는 다양한 변수의 선형조합에 의해 생성되며, 로딩값은 각 PC에 대한 변수들의 영향력을 나타낸다. 원본 스펙트럼(Fig. 4a)과 로딩값(Fig. 4c)은 Fig. 3a의 스코어 플롯에서 수초 한지의 데이터 포인트를 PC1의 양(+)의 영역으로 보내는 구동력이 카복실기로 할당된 1760 cm-1와 1720 cm-1 흡수대34)인 것을 보여준다. 반면, 로딩값은 문경 한지의 데이터 포인트를 PC2의 양의 영역으로 보내는 강한 구동력이 결정 셀룰로오스로 할당된 1315 cm–1 흡수대33)라고 제시하였다.
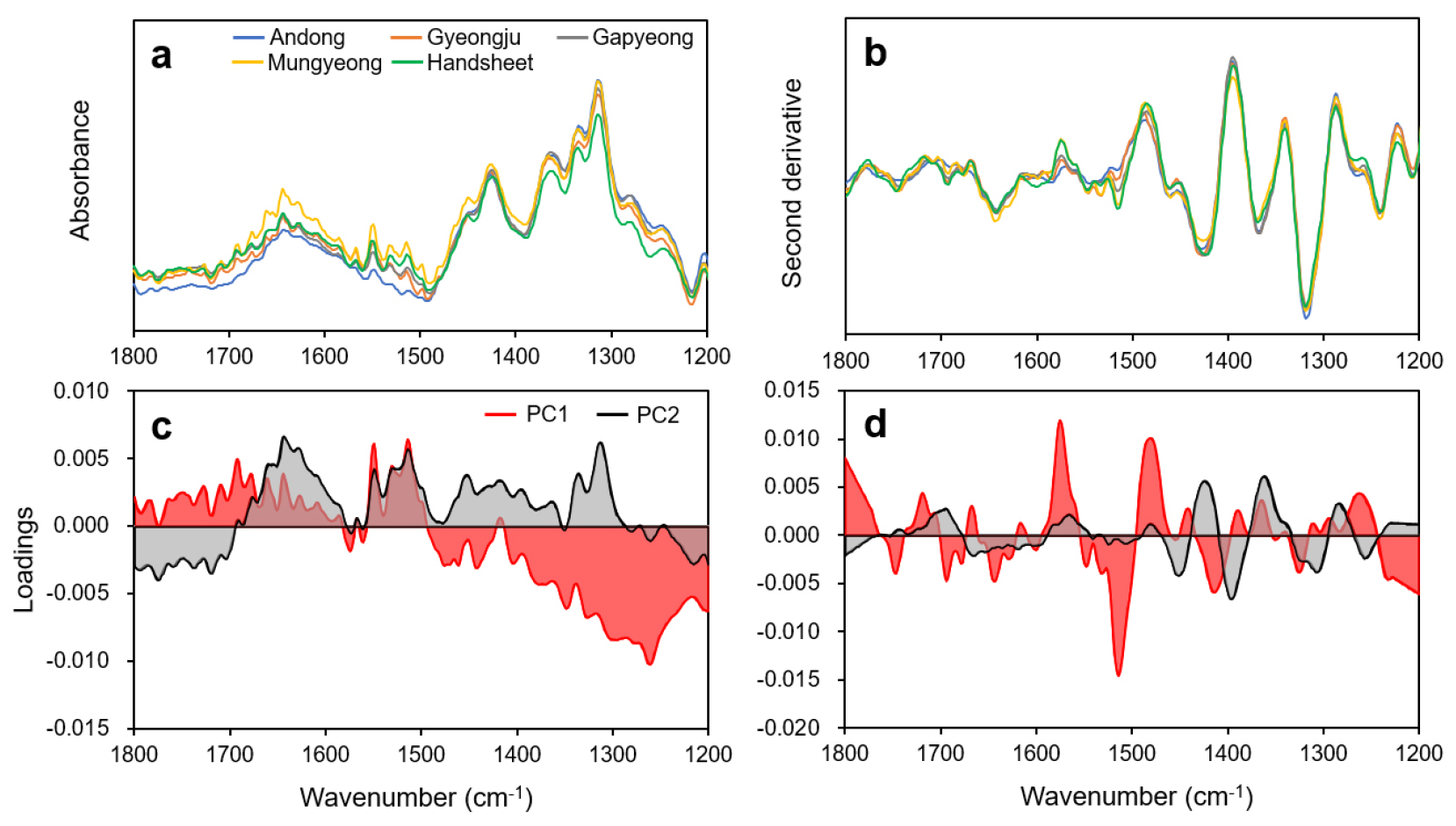
Fig. 3b의 2차 미분 스펙트럼(1800-1200 cm-1)에 대한 스코어 플롯에서는 데이터 포인트가 PC1을 따라 안동, 경주, 가평, 문경, 수초 한지의 순으로 배치되어 있다. Fig. 4b에서 종이의 유효 영역 중 PC1에 대한 높은 절대 로딩값(Fig. 4d)을 나타내는 영역은 방향족 고리에 할당된 1510 cm-1 흡수대였다.32) 방향족 고리는 한지의 주성분 중 리그닌에 대한 지표이다. 2차 미분 변환은 스펙트럼의 방향성을 반전시키므로 음수의 로딩값을 나타낸 방향족 고리는 스코어 플롯(Fig. 3b)에서 데이터 포인트를 양의 영역으로 위치시키는 데 기여한다. 또한, 지역별 데이터 포인트의 위치는 한지의 카보닐기 함량(Table 1)과도 관련이 있으며, 이는 IR 스펙트럼을 이용하여 카보닐기 관련 특성에 대한 예측 모델링이 가능하다는 것을 시사한다.
3.3 계층적 군집분석
계층적 군집분석의 결과물인 덴드로그램은 데이터 요소들 사이의 관계와 유사성을 시각적으로 보여준다. Fig. 5의 덴드로그램은 IR 스펙트럼으로부터 변환된 PC 데이터(PC1-PC6)에 대한 계층적 군집분석 결과를 보여준다. IR 스펙트럼을 이용한 계층적 군집분석에서도 Fig. 5와 동일한 구조의 덴드로그램이 생성되었는데, 이는 6개의 PC가 기존 IR 스펙트럼의 정보를 잘 보존한다는 사실을 보여준다.
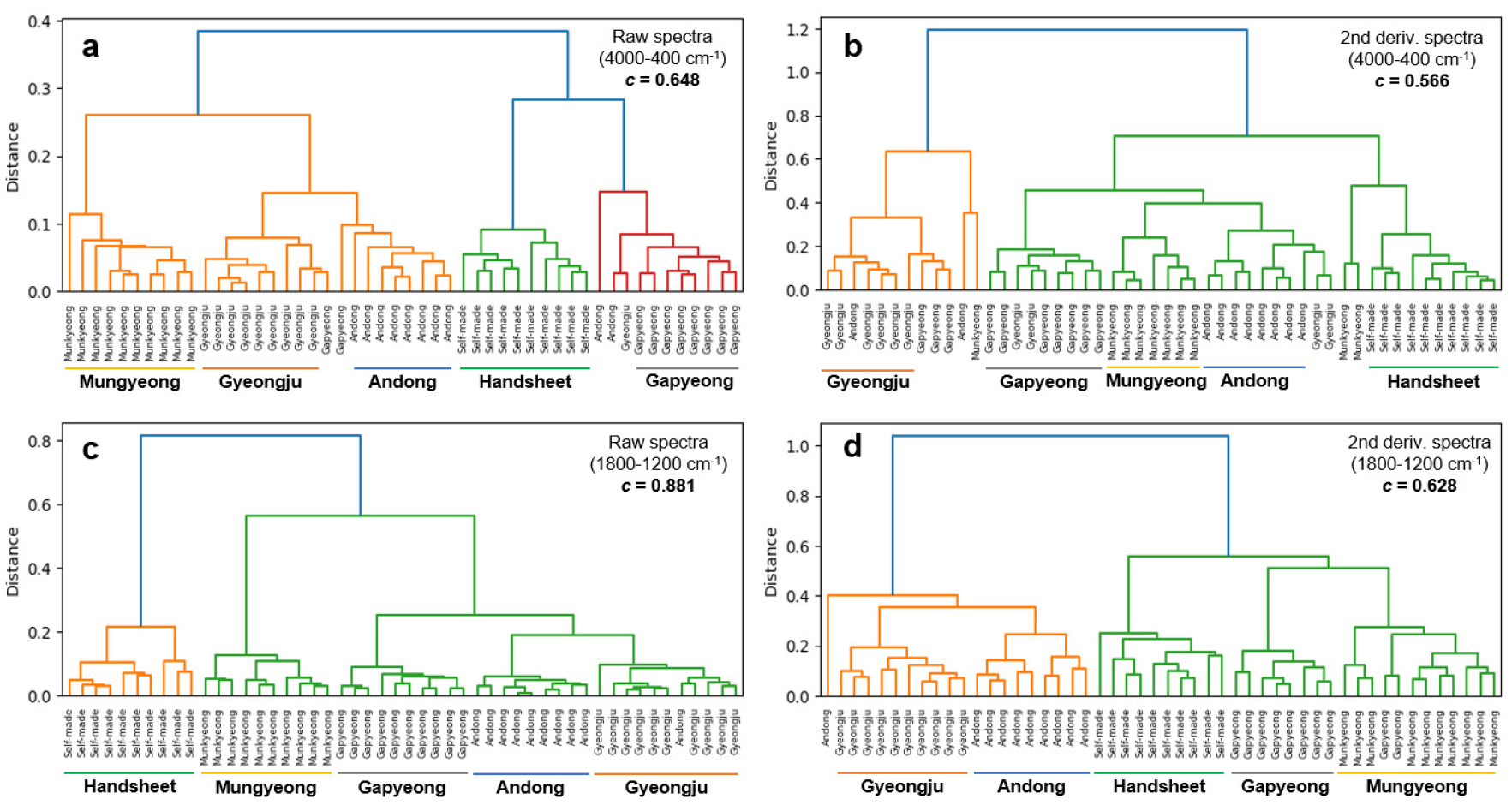
전체 영역의 원본 스펙트럼 기반 PC로부터 생성된 덴드로그램(Fig. 5a)에서 문경, 경주, 안동 한지는 서로 가까운 관계였으며, 이들은 수초 한지와 가평 한지와는 유사성이 낮았다. 이러한 데이터 분포는 닥나무 생산 지역과도 유사하였다(Table 1). 전체 영역의 2차 미분 스펙트럼 기반 덴드로그램에서 경주 한지는 다른 한지와 분리되었다(Fig. 5b). 그러나 수초 한지만이 온전한 클러스터를 형성했을 뿐 다른 지역의 한지 시료들은 일부 혼재되어 있었다. 이러한 결과는 2차 미분 전처리로 인해 지역별 구분이 불명확해진 Fig. 2b의 PCA 결과와 일치한다.
PCA의 스코어 플롯과 계층적 군집분석의 덴드로그램이 제시하는 한지의 지역별 관계는 다소 달랐는데, 이는 데이터 표현 방식의 차이에 기인한다. PCA는 데이터의 최대 변동성에 중점을 두지만, 계층적 군집은 데이터 포인트 사이의 유사성 혹은 비유사성을 기반으로 군집을 형성한다. 그리고 PCA의 스코어 플롯은 2개의 PC(PC1과 PC2)로 데이터 간의 관계를 표현하지만, 덴드로그램은 6개의 PC(PC1-PC6)로 관계를 시각화한다.
스펙트럼 영역을 1800-1200 cm-1로 한정했을 때 덴드로그램의 지역별 구분은 더욱 명확해졌다(Figs. 5c와 5d). 원본 스펙트럼 기반 덴드로그램에서 수초 한지는 다른 지역 한지들과 구분되는 군집을 형성하였으며(Fig. 5c), 군집의 분포는 Table 1에 제시된 카보닐기 함량의 차이와 유사하였다. PCA에 이어 계층적 군집분석에서도 IR 스펙트럼을 이용한 한지의 카보닐기 함량 예측의 가능성이 확인되었다. 2차 미분 데이터 기반 덴드로그램에서는 경주와 안동 한지가 가까운 관계를 형성했고, 반대편에서는 가평, 문경, 수초 한지가 서로 가까웠다. 이러한 양상은 증해 약품의 차이와 일치한다(Table 1).
군집분석에서 경주와 안동 한지는 서로 가까운 관계를 유지했다. 두 지역에서 제조된 한지들은 닥나무 생산 지역이 비슷하고 동일한 증해 약품을 사용하며, 카보닐기 함량이 유사하였다. 경주와 안동 한지 간의 관계만큼은 아니지만, 가평과 문경 한지도 서로 가까운 관계를 유지했다. 이 두 지역은 증해 과정에서 메밀대로 만든 천연 잿물을 사용했다는 공통점이 있다. 수초 한지는 특정 지역과 일정한 관계를 나타내지는 않았지만, PCA와 계층적 군집분석 모두에서 문경 한지와 비교적 가까운 것으로 확인되었다.
3.4 분류 모델 평가
데이터의 유사성을 기반으로 숨겨진 패턴과 구조를 발견하기 위한 비지도 학습인 군집분석과는 달리 분류는 데이터 포인트를 사전 정의된 카테고리로 할당하는 지도학습 기법이다. Table 2는 한지 제조 지역 판별을 위해 IR 스펙트럼 데이터로 학습된 FNN 모델의 분류 성능을 나타낸다. 전체 영역의 원본 스펙트럼 및 2차 미분 스펙트럼으로 학습된 모델의 한지 제조 지역 분류에 대한 정확도는 각각 0.933과 0.800으로 나타났다. PCA와 계층적 군집분석에서 확인되었던 것처럼 스펙트럼 데이터의 2차 미분 전처리는 분류 성능을 개선하지 못했고, 오히려 정확도는 감소하였다.
Fig. 6의 혼돈 행렬은 전체 스펙트럼 영역으로 학습된 모델의 한지 분류 결과를 나타낸다. 원본 데이터로 학습된 모델의 경우 경주 한지 시료 1개가 가평으로 오분류되었다(Fig. 6a). 그리고 2차 미분 데이터로 학습된 모델에서는 경주 한지 시료 2개가 가평으로 오분류되었고, 문경 한지 시료 1개가 경주로 오분류되었다(Fig. 6b). 이러한 오분류는 Figs. 5a와 5b의 덴드로그램에서도 확인할 수 있다.
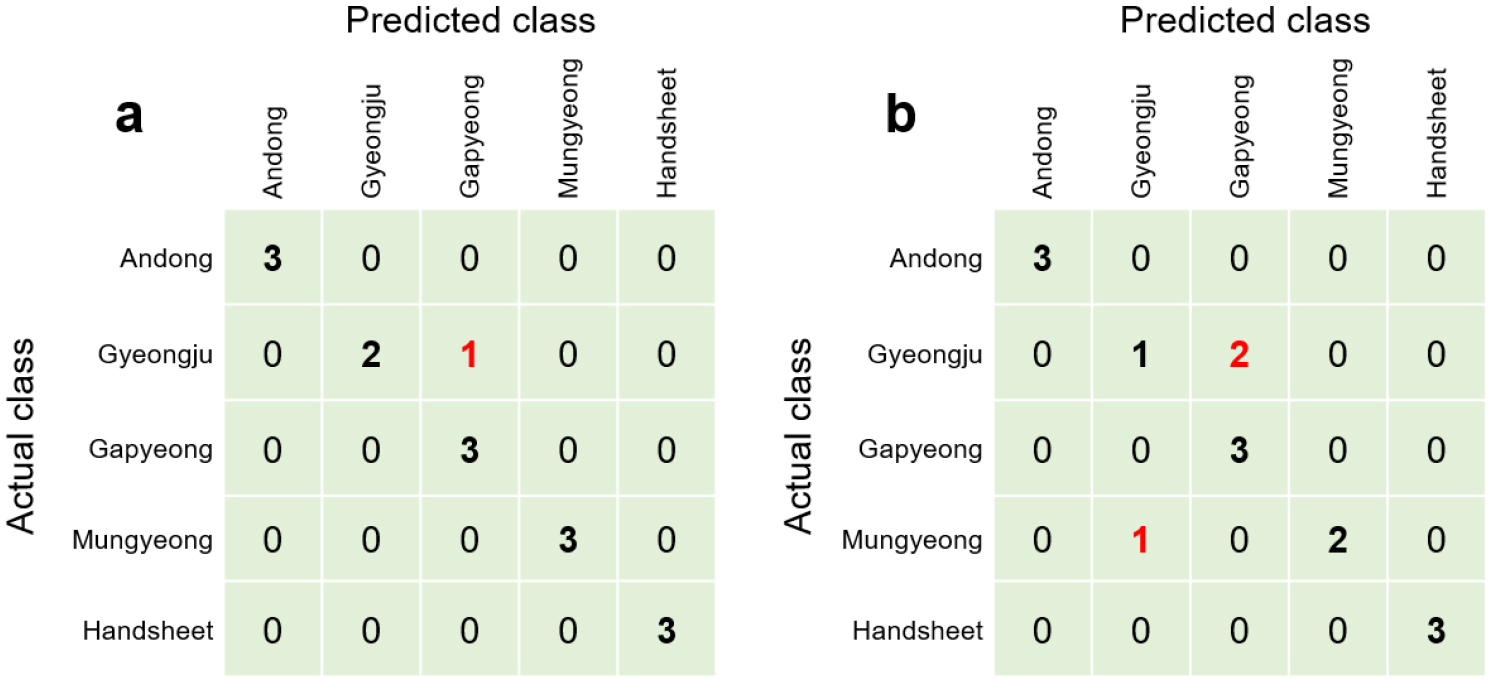
전체 스펙트럼 영역 기반 모델과는 대조적으로 1800-1200 cm-1 영역의 스펙트럼을 학습한 모델은 원본 및 2차 미분 데이터에서 모두 100%의 분류 정확도를 보였다. 이러한 결과는 시료를 특성화할 수 있는 데이터의 선택적 이용이 분류를 위한 좋은 전략임을 입증하며, 1800-1200 cm-1 영역이 한지의 특성을 잘 반영한다는 것을 시사한다. 스펙트럼 데이터를 이용한 다양한 분류 문제에서 입력 변수의 축소와 선택은 모델 성능 개선과 계산 비용 감소를 위한 효과적인 방법이라 할 수 있다.9,10)
Table 2의 ‘Parameter’를 보면 한지 분류를 위해 선정된 FNN 모델은 모두 하나의 은닉층으로만 구성된 것을 확인할 수 있다. 본 연구에서 다양한 수의 노드를 가진 1개 혹은 2개의 은닉층으로 구성된 인공신경망 네트워크를 실험했으나 실제 분류에서는 가장 적은 수의 노드와 하나의 은닉층으로 구성된 가장 간단한 모델이 가장 높은 분류 결과를 달성하였다. 한지 분류에 심층 신경망과 같은 더 복잡한 구조가 필요하지 않았다는 사실은 한지의 IR 데이터가 복잡한 패턴이나 관계를 보이지 않다는 것을 암시한다.
Table 2.
Classification performance of feed-forward neural network models trained with infrared spectra for discriminating manufacturing regions of Hanji
|
Wavenumber (cm-1) | Preprocessing | Accuracy | Parameter | |
| Training | Test | |||
| 4000-400 | Raw | 1.000 | 0.933 | hls=(1000,), lr=0.0001, solver=adam |
| 2nd deriv. | 1.000 | 0.800 | hls=(100,), lr=0.01, solver=adam | |
| 1800-1200 | Raw | 1.000 | 1.000 | hls=(100,), lr=0.01, solver=sgd |
| 2nd deriv. | 1.000 | 1.000 | hls=(100,), lr=0.1, solver=sgd | |
3.5 분류 성능 비교
FNN 모델은 IR 스펙트럼을 학습하여 한지의 제조 지역 분류에 성공했다. 훈련 세트에 대한 오류가 같다면 더욱 단순한 모델의 일반화 오류가 더 낮을 가능성이 크다는 Occam의 면도날 이론35)을 고려한다면, 계산 비용이 비교적 높은 인공신경망 모델보다 더 간단한 모델이 한지 분류에 더욱 적합할 수도 있다.
Table 3은 FNN, SVM 및 KNN 모델의 한지 제조 지역 분류에 대한 성능을 보여준다. FNN은 선형 모델과 비선형 함수들의 결합으로 이루어진 비선형 모델이며, SVM과 KNN은 선형 모델이다. 계산 비용은 FNN, SVM, KNN 순으로 높다. 전체 스펙트럼 데이터를 학습한 경우, SVM 모델은 원본 및 2차 미분 전처리 데이터 모두에 대해 FNN과 같은 분류 성능을 달성했다. SVM은 선형 모델이지만 커널 트릭을 사용하여 데이터를 고차원 특징 공간으로 투영하여 비선형 분류를 수행할 수 있다.
Table 3.
Performance comparison of FNN, SVM, and KNN models for classifying manufacturing region of Hanji
반면, KNN 모델은 원본 및 2차 미분 데이터에 대한 분류 정확도가 각각 0.800과 0.733으로 다른 두 모델보다 성능이 낮았다. KNN 알고리즘은 훈련 데이터의 학습 없이 거리 기반으로 입력된 데이터 포인트를 분류하는 매우 간단한 모델이다. 비록 본 연구에서 사용한 데이터 세트는 적은 수(50개)의 시료로 구성되었지만, 각 스펙트럼 데이터는 2,545개의 상당히 많은 변수로 구성되어 있다. 따라서 스펙트럼 데이터를 이용한 한지의 분류에는 KNN보다는 계산 복잡도가 높은 모델이 적합한 것으로 판단된다.
제한된 스펙트럼 영역(1800-1200 cm-1)의 데이터를 학습하였을 때 모든 모델에서 100% 정확도의 분류 성능이 달성되었다. 선택된 스펙트럼 영역이 한지의 특성을 잘 드러내는 영역임이 재차 확인되었다. 이상의 모델 성능 비교를 통해 IR 스펙트럼을 이용한 한지의 제조 지역 분류에는 KNN보다는 계산 복잡도가 높은 FNN과 SVM이 더욱 적합한 것으로 확인되었다. 본 연구에서 사용된 데이터 세트 규모에서는 계산 복잡도는 낮으면서 비선형 분류를 수행할 수 있는 SVM을 인공신경망의 대안으로 고려할 수 있다. 단 데이터 규모가 달라지면 모델 적합도는 다시 평가되어야 한다.
3.6 한지의 지역적 특성에 대한 고찰
본 연구로부터 IR 분광법과 인공신경망의 결합이 한지의 제조 지역 분류를 위한 좋은 전략임이 확인되었다. 그러나 국산 한지에 지역적 특성을 부여할 수 있는지에 대해서는 논의할 필요가 있다. 국내 한지 공방의 닥나무 원료 입수 경로는 다양하며, 지역 닥나무를 사용하지 않는 경우는 원료의 지역적 특성화가 어려울 수 있다. 또한, 한지 제조 시기 및 배치(batch)에 따라 원료 조성이 달라진다. 이러한 사항들을 고려한다면 본 연구에서 확인된 한지의 제조 지역 분류가 증해 및 표백과 같은 제조방식 차이에 의한 한지 공방별 시료 분류의 결과일 수 있음을 염두에 두어야 한다.
한지의 지역적 특성화의 가능 여부를 검증하기 위해서는 같은 지역 기원의 닥나무를 다른 방식에 의해 제조된 한지, 그리고 다른 지역 기원의 닥나무를 같은 방식에 의해 제조된 한지를 대상으로 한 포괄적인 조사가 필요하다. 이러한 맥락에서 한지를 비롯한 다양한 종이 재료의 특성화를 위한 기계학습 기반의 연구가 수행 중이며, 해당 연구 결과는 추후 보고할 예정이다.
4. 결 론
한지의 제조 지역 판별을 위해 IR 스펙트럼 데이터로 학습된 인공신경망 기반의 FNN 분류 모델을 구축하였다. 노이즈가 많은 원본 스펙트럼 데이터에 대한 2차 미분 전처리는 모델의 분류 성능 향상에 도움이 되지 않았으며, 오히려 성능 저하를 초래하였다. 반면 종이의 특성을 잘 반영하는 스펙트럼 영역(1800-1200 cm-1)의 선택적 학습 전략은 모델의 분류 성능을 개선하였다. 선택된 스펙트럼 영역을 학습한 모델들은 모두 100%의 정확도로 한지의 제조 지역을 분류하여 분광 데이터와 결합한 기계학습 기반 접근의 유용성을 확인하였다. PCA와 계층적 군집분석의 결과로부터 한지의 제조 지역 분류를 넘어 원료 및 화학적 특성에 대한 예측 모델링의 가능성이 확인되었다.
