

1. Introduction
2. Materials and Methods
2.1 Materials
2.2 Methods
3. Results and Discussion
3.1 Analysis of X-ray spectra
3.2 Data dimension reduction and partition
3.3 Model evaluation indexes
3.4 Result visualization analysis
4. Conclusions
1. Introduction
Stacked sheets counting is an important operation in paper and printing industry, such as the in-line binding process of book printing, high-level printing and security labeling fields.1) The traditional manual counting methods by measuring the physical attributes of a pack, obtaining the total and average parameters of weight or height, and the number of stacks can be obtained by division. Manual counting is the most primitive counting method, which is extremely tedious and can lead to counting errors due to the individual attribute differences.2) Some in-line contact technologies can also be used for paper thickness measurement, such as magnetic reluctance and eddy current sensors. Magnetic sensors can provide kHz sampling rate and high accuracy up to micrometer precision. However, they need to contact on both sides of the paper and compress stacks under a fixed pressure,3) worse still, the paper can be easily damaged by these mechanical operations.4) In general, these traditional methods have the disadvantages of low efficiency, breakage and inaccurate counting.
Some non-contact measurement methods have been applied to stacked sheets counting in recent years. They can be divided into two categories: based on machine vision technology and using radioactive rays. In the method of machine vision, Sato, J. et al. detect the boundaries of stacked facial oil blotting papers for counting,5) but this method can be confused with the paper boundary and crease. Han, X. et al. propose a stacked paper counting approach based on image texture.6) However, this approach is only suitable for regular stacks, which is difficult to apply in practical production. Zhu, H. et al. build a counting system for ultra-high stacks,where the camera array is used to capture the edge texture images of the packed papers.7) Xiao, C. et al. use local histogram equalization algorithm and bi- Gaussian linear enhancement algorithm to detect the low contrast images of stacked white paper sheets.8) However, it needed a priori knowledge of the template size for histogram equalization. The above detection methods require the sheets to be stacked regularly, i.e., the edge characteristics of each substrate must be shown. In addition, these methods are not suitable for stacked sheets with transparent material, rough edge, low edge resolution, too thin substrate, and sticking sheets, as the contour features cannot be clearly shown in these situations. Zhao, H. et al. design a stripe detection method, using local template matching algorithm and a global frequency domain filtering algorithm.9) This approach can accurately count when the substrates are distorted and irregularly stacked. Pham, D. et al. use a U-Net network for the segmentation and counting of stacked sheets,10) and this method can solve the interference caused by rough edges, low edge resolution, and adhering sheets. However, there are still some challenges that cannot be overcome, such as transparent substrates, hidden sheets, and sheets that are too thin.
In the radioactive ray measurement, the X-ray thickness gauge is commonly used. When the X-ray penetrates objects of different thickness(d), the detector receives different X-ray intensities(I), the object is thicker, the received X-ray intensity is weaker, taking advantage of this property, the thickness of the object can be obtained.11) However, there’s no model that can well build the relationship between d and I. Shi, Y proposes a liner interpolation model for gamma ray thickness gauge,12) but the accuracy of the model depended on the number of calibration plate. As the number of plate increased, the calibration time increased dramatically. Unlike the gamma rays, which are mono-energetic ray, the multi-energetic X-ray suffer from hardening phenomenon in the transmission process. Xu, G. et al. develop a non-linear model to fit the X-ray attenuation process,13)but there is an estimation error in solving the model parameters. Generally, a five degree polynomial model is used in X-ray thickness gauge.14) However, for a large measurement range, it needs piece-wise fitting to reduce the model’s error. Additionally, the total thickness of calibration plates should cover the whole measurement range.
Based on the above problems, a fast in-line counting method based on photon counting detector (PCD) was proposed. 500 A4 papers were prepared to collect X-ray absorption spectra (XAS) data. After the data were preprocessed by principal component analysis (PCA), three counting models were constructed: polynomial fitting model (PFM), artificial neural network (ANN) and long short-term memory network (LSTM). The main data features extracted by PCA were used to train these models.
2. Materials and Methods
2.1 Materials
2.1.1 Instruments and data acquisition
The schematic diagram of the broadband XAS detection equipment was shown in Fig. 1. This equipment was designed by our laboratory.15) The lead shell of the equipment could avoid X-ray radiation leakage, and the experimental samples were isolated from the external environment.
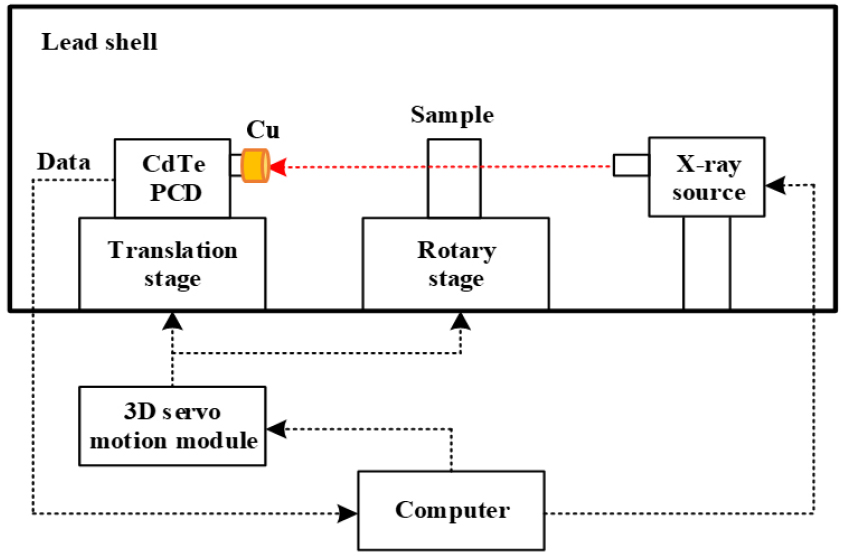
The core components of the detection equipment included a three-dimensional (3D) servo motion module, an X-ray source, and a CdTe photon counting detector (PCD). The 3D servo motion module could control the translation of the PCD and the rotation of the rotary table. The cone beam X-ray source was manufactured by American MOXTEK Company, and its model number was 60 kV-12 W MAGPRO. This X-ray source was a tungsten target X-ray tube, and the tube voltage range was 4-60 kV, the tube current range was 0-1000 μA, the focal size was 400 μm, and the maximum power was 12 W. Through the translation stage, the PCD could be adjusted on the same line. The rotary stage could fine-tune stacked sheets so that they were vertical with the X-ray source.
The CdTe PCD was manufactured by American Amptek Company, and its model number was X-123. The PCD was a semiconductor detector with an energy resolution of <1.2 keV. The photon energy channels of CdTe PCD were separated, and the number of photons in each photon energy channel was obtained. The PCD had 512 photon energy channels, and the calibration relationship of photon channel and energy was given by Eq. 1.15)
where, n was the photon channel, E (eV) was the photon energy. A collimator (Cu cap, outer diameter 24 mm) was used to remove the scattered X-ray photons. The sample and experimental platform were shown in Fig. 2. The sample was placed 125 mm from the PCD and 475 mm from the X-ray source. A fan-beam laser of 650 nm wavelength was used to indicate the center of the X-ray source and the Be window of the PCD to ensure that they were at the same level.

According to relative works,16) and through extensive tests, the X-ray tube voltage was set at 40 kV and the X-ray tube current was set at 8 μA, and each X-ray spectrum was measured for 30 s. Five hundred sheets of standard A4 printing paper (70 g/m2) were taken as experimental samples, and the papers were produced by Deli Company. To reduce the differences in individual characteristics, these papers were from the same package, so the production and storage environments were similar. Finally, the X-ray transmission spectra of 1 to 500 sheets of paper were measured.
2.1.2 XAS data preparation and preprocessing
When a single-energy X-ray of incident intensity I0 penetrated a homogeneous medium of thickness d, the X-ray intensity was attenuated to I. The attenuation process could be described by the Beer- Lambert law,17) and was given by Eq. 2:
where, u was the X-ray attenuation coefficient, which was related to X-ray absorption and scattering effects. However, X-ray scattering effect could be negligible in this experiment. On the one hand, due to the PCD received data were composed with hundreds of channels and analyzed as an integration. The distorted XAS data caused by scattering effect were inputted into the models (details in section 2.2), which learnt the non-linear relationship between XAS and stacked sheets number. The scattered photons in multiple channels could not have an obvious affection on the results, especially for the proposed neural network models. On the other hand, the scattering occurred little as the penetrated stacked paper sheets (main components were carbon, hydrogen, and oxygen) had a low atomic number. Therefore, the X-ray absorption coefficient μ could be calculated by Eq. 3.
The X-ray photon measured by PCD was approximated as monoenergetic X-ray in each photon energy channel. The X-ray absorption coefficient in each photon energy channel was calculated from the incident and transmitted X-ray spectrum, and the broadband XAS in a certain photon energy range was obtained. Eq. 3 showed that the sample’s thickness d was related to attenuation index u at a given incident X-ray energy. Therefore, stacked sheets counting could be achieved theoretically.
In this experiment, 500 X-ray incident spectra and transmitted spectra were measured, and the broadband XAS were calculated via Beer-Lambert law. Then, the XAS data were normalized to 0–1 in order to eliminate the interference of singular data. In addition, normalization could accelerate gradient descent for getting the optimal solution of the model.18)
As the original XAS data had 165 features, which were an overload for the lightweight model and not suitable for real-time processing. Common data dimension reduction techniques include: linear discriminant analysis (LDA),19) factor analysis (FA),20) principal component analysis (PCA),21) and singular value decomposition (SVD).22) Since PCA was a relatively simple and effective dimension reduction method, so it was used to reduce the dimension of XAS data. Sample of XAS data X as example:
where, , then compressed each feature as follows:
Calculating the covariance matrix and do eigenvalue decomposition, ranking the eigenvalues from large to small, taking the largest eigenvector of the first d eigenvalues to form the feature transformation matrix W:
Finally, the principal component of the initial XAS data could be represented by P:
Using P as a replacement for the original XAS data, the data dimension was reduced, and most of the content could be retained.
2.2 Methods
Three models were constructed to establish a relationship between the pre-processed XAS data and the number of stacked sheets, and the performance of these models was compared.
2.2.1 Polynomial fitting Model
Polynomial fitting model (PFM) was widely used in X-ray thickness gauge,11) it could be written as Eq. 8.
where d was the thickness of the object, and I was the transmitted X-ray intensity. In this experiment, d was the number of stacked sheets, and I was the number of X-ray photons received by the PCD. The index n was important for model’s accuracy, and should be chosen carefully. A smaller degree led to a lower fitting accuracy, a larger degree could get a better result but increased the complexity of the calibration. To achieve a balance between model accuracy and calibration effort, the polynomial degree was set to five.14)
2.2.2 Artificial neural network
An artificial neural network (ANN) model was constructed to establish a relationship between XAS data and stacked sheet thickness. ANN was composed of many neurons, and in theory, a neural network with a single hidden layer containing a finite number of neurons and a nonlinear activation function could fit any nonlinear function.23,24) The structure of ANN mainly included input layer, multi- hidden layers, and output layer. It consisted of many functions like Eq. 9:
where was the activation function of the hidden layer, was the weight of the neuron node, and was be offset.
As XAS data belonged to 1 dimension (1D) data and its complexity was reduced by PCA, so the network was constructed with only two dense layers. This could capture the features of XAS data and avoid overfitting. Rectified linear unit (Relu) was a kind of nonlinear activation function that could avoid vanishing gradient and exploding gradient, it was shown as the following formula:
The nonlinear activation function sigmoid was also known as the logistic function, which could map the data between 0 and 1. Sigmoid could be expressed as:
Relu was taken as the activation function of the hidden layer, sigmoid was taken as the activation function of the output layer. The optimized values of the main hyper-parameters of the ANN were shown in Table 1.
Table 1.
The optimized values of ANN hyper- parameters
2.2.3 Long short-term memory network
As XAS data is one dimensional data, and in stacked sheets counting scenes such as book binding and paper packaging, the paper sheets were stacked one by one, the current XAS data was related to the previous stacked sheets. Therefore, to a certain extent, the XAS data had temporal sequence property. Long short term memory network (LSTM) is good at addressing 1D data especially those with temporal properties.25) It can selectively retain the information of previous layers. The structure of LSTM was depicted in Fig. 3. It consisted of many timestep. Taking the t timestep as an example, namely the middle block in the model, there were three inputs and two outputs, the input was the cell state information of t-1 timestep, the input was the output of t-1 timestep, and the input was the input of t timestep, namely the XAS data sequence. It meant that using the XAS data from to timestep to predict the number of stacked sheets at timestep. The output was the reserved state information of t timestep and was the output of current timestep. Noted that all the input and output variables were vectors. The internal computations in the t timestep were as follows:
where,
and could be calculated as:
where was called forget gate. It decided the probability of preserving the information of the last timestep . As it was caculated by sigmoid activation function 𝜎, it belonged to [0, 1]. How much of the current timestep’s information was contained depending on the input gate and the current input information . The activation functions were sigmoid and tanh respectively, and the current timestep reserved state information screened by Eq. 13. The final output was calculated in Eq. 14, which was decided by the output gate . The gate selected how much content should be released at this timestep, the was also activated by sigmoid function.
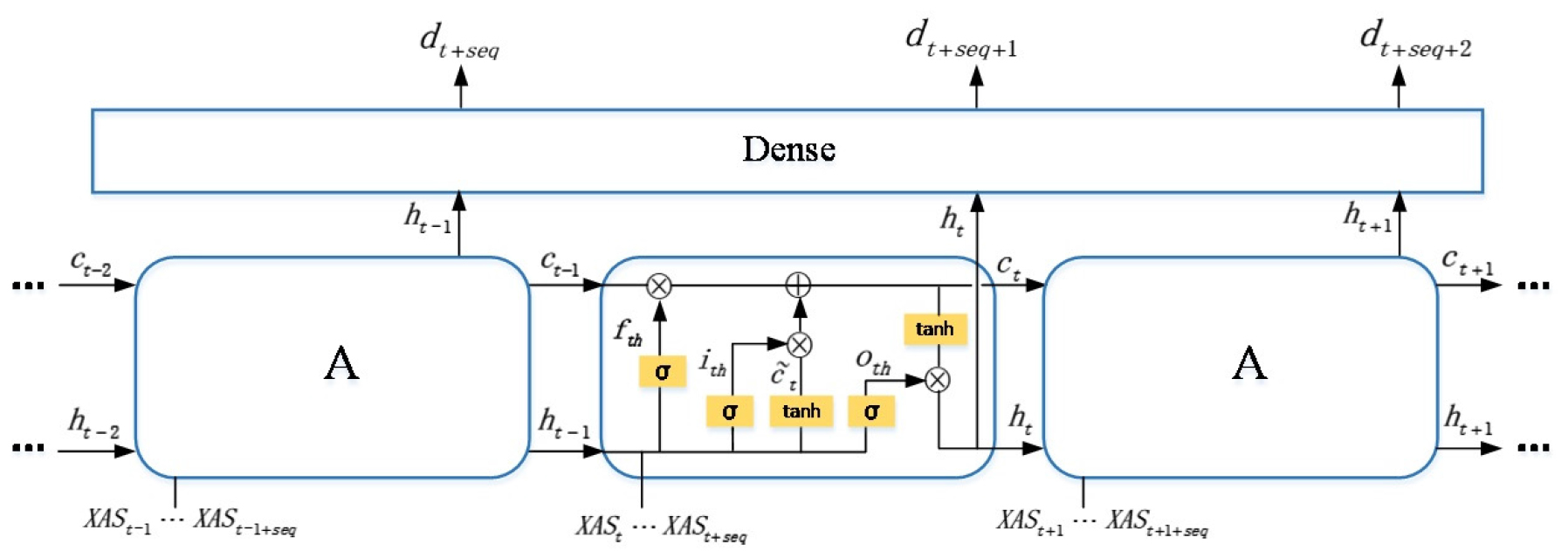
The current timestep’s output (multi-dimensional vector) was inputted to the next dense layers, which gradually converged the multi-dimensional data () to one dimension, namely the number of stacked paper sheets. The optimized hyperparameters of LSTM were shown in Table 2.
Table 2.
The optimized values of LSTM hyper- parameters
3. Results and Discussion
3.1 Analysis of X-ray spectra
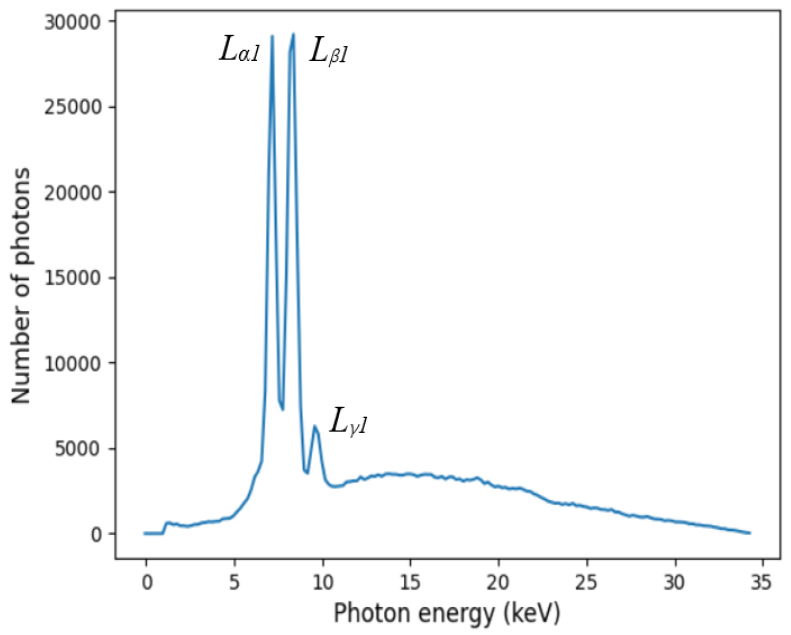
In this experiment, the X-ray tube voltage was set at 40 kV and the X-ray tube current was set at 8 μA after extensive experiments. The measured X-ray incident spectrum was shown in Fig. 4. There was no sample placed on the rotary table. Tungsten (74W) was the anode (target) material for the X-ray source, and the incident spectrum was the L-series excitation spectrum of tungsten. In Fig. 4, The y-coordinate was the number of X-ray photons measured by the CdTe PCD, and the x-coordinate was the photon energy. The incident spectrum had three characteristic peaks of Lα1, Lβ1, and Lγ1, and the photon energy of the peaks were Lα1 = 8.3976 keV, Lβ1 = 9.6724 keV, Lγ1 = 11.2859 keV.
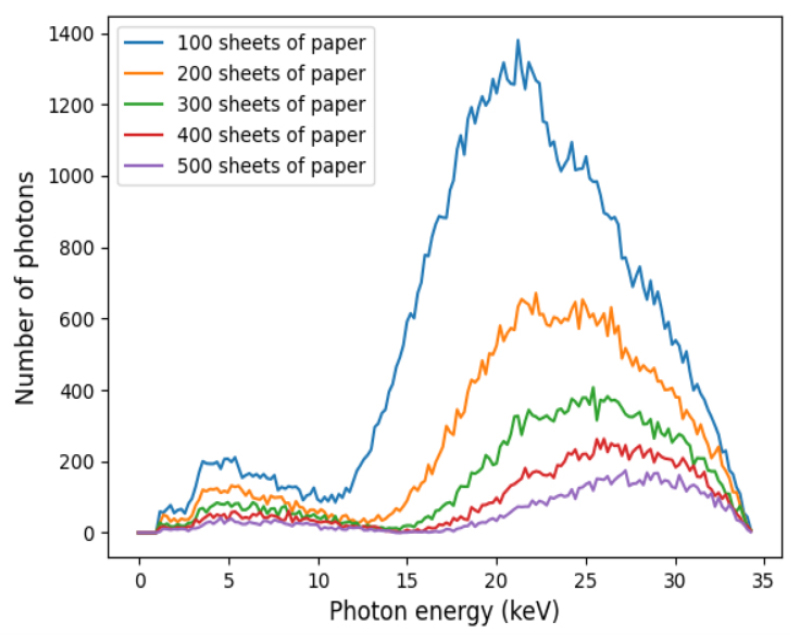
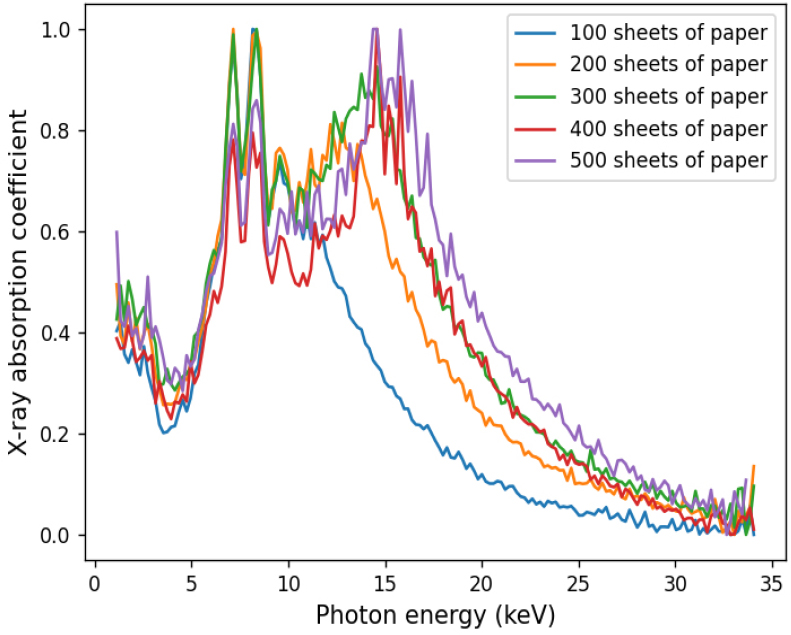
Since the numbers of stacked papers were up to 500, only the X-ray transmission spectra and XAS of 100 sheets, 200 sheets, 300 sheets, 400 sheets and 500 sheets were plotted in Fig. 5 and Fig. 6. They showed that there were obvious discrepancies in the XAS for different numbers of stacked papers, especially in the photon energy range from 10 keV to 34 keV. With the differences existing in the XAS of different numbers of stacked papers, the proposed models could build the relationship between XAS data and stacked papers.
3.2 Data dimension reduction and partition
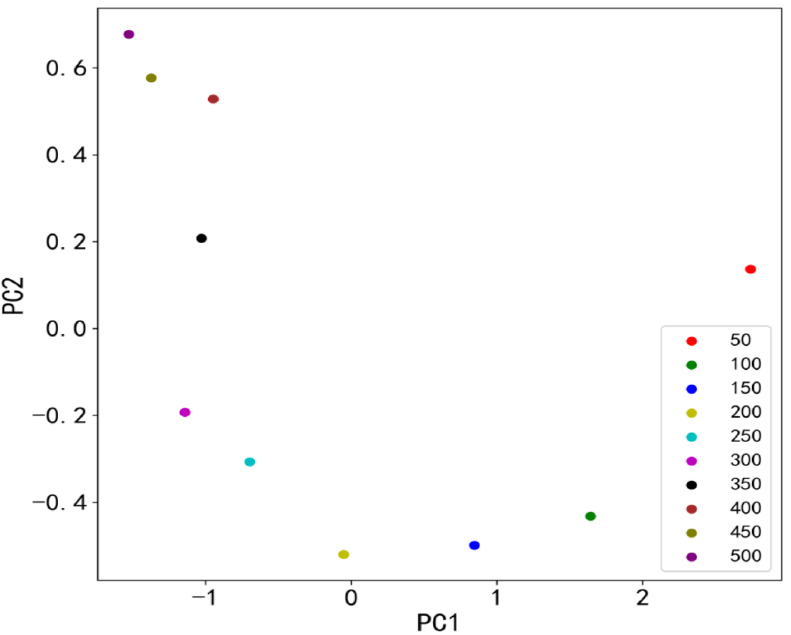
As discussed in 2.1.2, the PCA algorithm was used to reduce the dimension of XAS. The contribution rate and cumulative contribution rate (CCR) were shown in Table 3. It showed that the CCR of the top 5 principal components reached 96.56% (>95%,26)), which meant that if the top 5 principal components were used to substitute the original XAS data, then 96.56% of the original content could be remained. The distributions of the top 2 principal components were shown in Fig. 7. These results showed that the top 2 principal components could effectively discriminate between different numbers of stacked sheets. In this experiment, the top 5 principal components were taken as input of the three models.
Table 3.
Contribution rate and cumulative contribution rate of the top 5 principal components
| Principal component | Contribution rate (%) | Cumulative contribution rate (%) |
| PC1 | 79.88 | 79.88 |
| PC2 | 7.81 | 87.69 |
| PC3 | 4.97 | 92.66 |
| PC4 | 2.82 | 95.48 |
| PC5 | 1.08 | 96.56 |
For the ANN and LSTM models, 10% of the data set was randomly selected as the test set, and the remaining 90% of the data set was randomly divided into a training set and validation set with a ratio of 9:1. The PFM was fitted using the method in.13) According to Eq. 8, each pair of fitting points (d, I) consisted of the sheets number d and the transmitted X-ray density I. The fitting points including the minimum, maximum and other points were evenly distributed in all 500 stacked sheets, and the PFM was tested on the rest points. The training computer was configured with 16 CPU cores (2.9GHz, i7-10700F), 32GB RAM and a GPU (NVIDIA GeForce RTX3060).
3.3 Model evaluation indexes
Mean square error (MSE), mean absolute error (MAE), max absolute error (MAXE) and Coefficient of determination (R2) were selected as evaluation indexes of the above models. MSE and MAE recorded the prediction accuracy in different dimensions. MAXE reflected the worst prediction accuracy of the model. The smaller values of MSE, MAE and MAXE led to the higher fitting accuracy of the model. R2 recorded the overall fitting accuracy of the model, and the value of R² ranged from -∞ to 1. The closer R² was to 1, the better the fit. The evaluation indexes were shown in Eqs. 15, 16, 17, 18.
where n was the total number of test set, and were the true and predicted values of the i-th data respectively, and was the mean value of .
3.4 Result visualization analysis
The MSE, MAE, MAXE, and R2 of PFM, ANN and LSTM were shown in Table 4, and the bold values were the better results among these models. It showed that all the index results of LSTM were better than those of PFM and ANN. However, the results of PFM were better than ANN. It may be the PFM was fitted by five degree polynomial, which was more expressive than ANN (fitted by two fully connected layers). The errors between the actual number of stacked papers and the predicted values by PFM were drawn in Fig. 8. The horizontal axis represented the log value of X-ray transmission intensity, and the greater transmission intensity represented the less stacked papers had been penetrated. As shown in Fig. 8, the predicted values agree well with the actual values when the stacked sheets were more than 20. However, when the penetrated papers decreased, the PFM could not get a good performance. This was because the thinner samples the less X-ray attenuation could be detected, so there were less differences between incident and transmitted X-ray intensity, which was important for the accuracy of PFM.
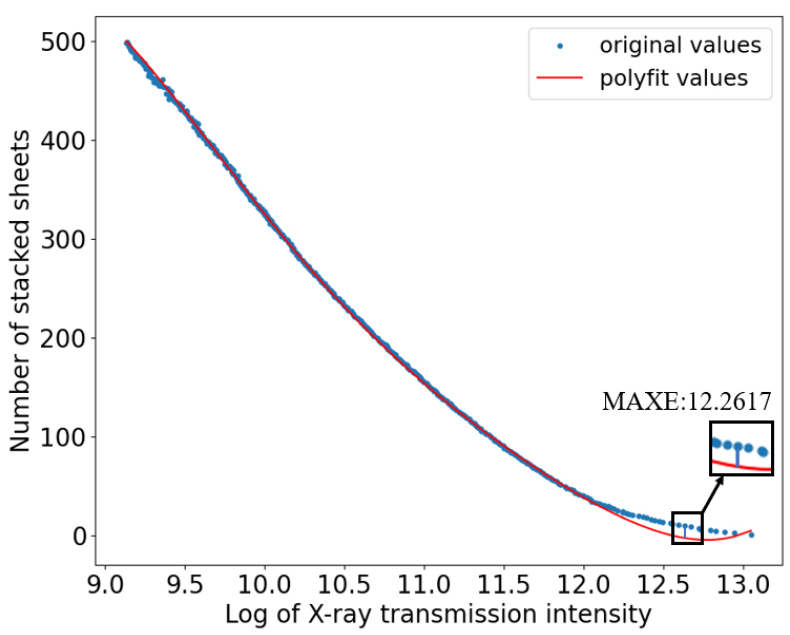
Table 4.
The index results of PFM, ANN and LSTM
| Model | MSE (sheet) | MAE (sheet) | MAXE (sheet) | R2 |
| PFM | 9.4004 | 2.1032 | 12.2617 | 0.9995 |
| ANN | 35.5828 | 3.5656 | 22.4591 | 0.9981 |
| LSTM | 0.5236 | 0.5197 | 1.8504 | 0.9999 |
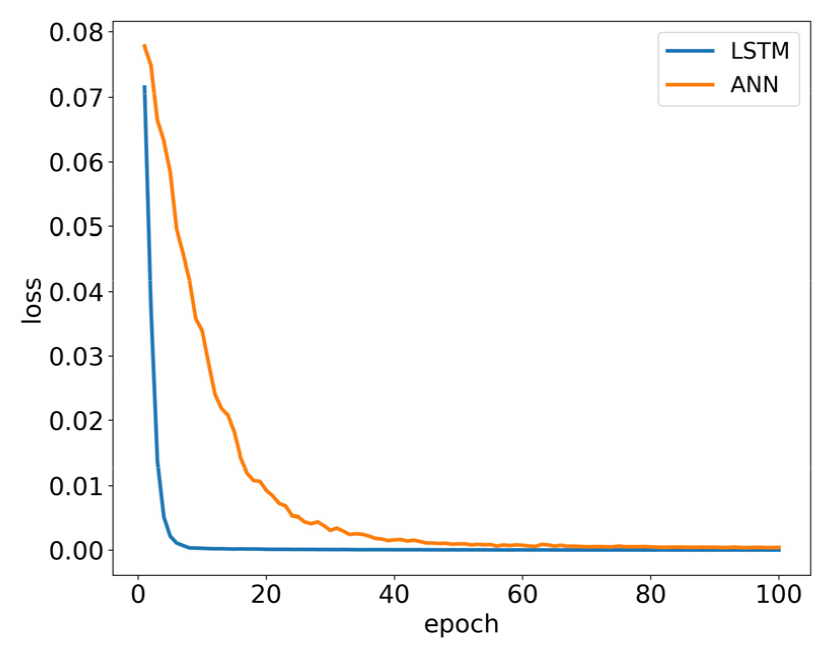
The two artificial neural networks (ANN and LSTM) built non-linear relationships between XAS data and stacked sheets. The training processes of the models were shown in Fig. 9. It could be seen that LSTM converged faster than ANN, and the loss curve of LSTM was also below that of ANN. It meant that the proposed LSTM model was more suitable for this task than ANN. This could also be evidenced in Fig. 10 and Fig. 11. From the results of the two models, we could intuitively find that the errors of ANN were much larger than that of LSTM. In the test data of ANN, the MAXE 22.4591 occurred when the number of stacked sheets was 402. The negative value meant that the predicted value was less than the true value, and the MAXE of LSTM was 1.8504, which occurred when the number of stacked papers was 444 sheets.
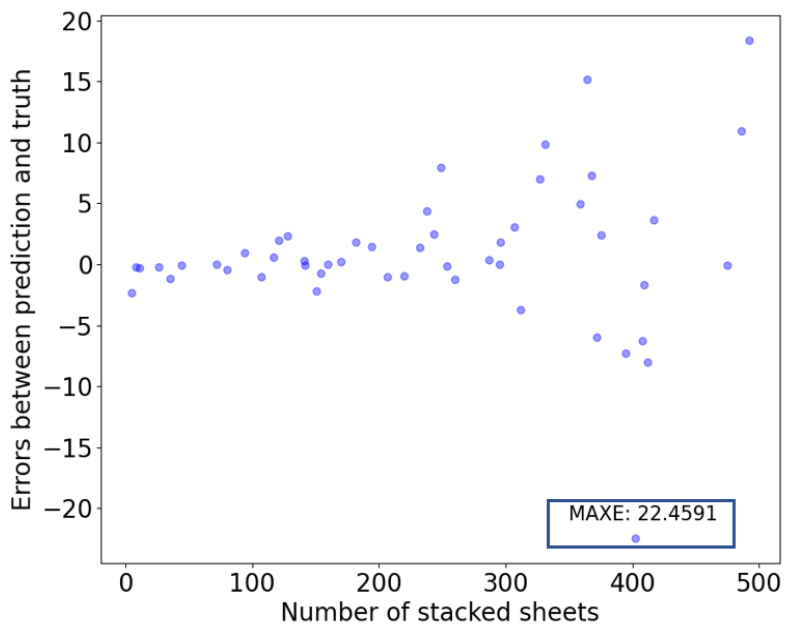
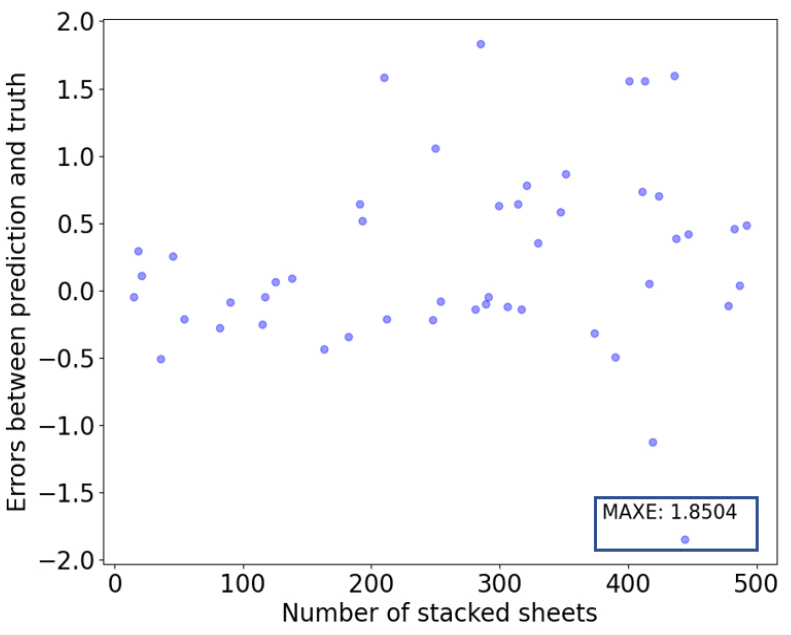
From the above analysis, we could see that the accuracy of these two neural networks was not affected by thinner stacked sheets, which was different from PFM. For the both two models, the prediction errors of the thinnest stacked sheets were smaller than those of the thickest stacked sheets.
Compared with the commonly used PFM in X-ray thickness measurement, the combination of XAS with neural networks (ANN and LSTM) took full advantage of absorption attenuation in separate energy channels, and the XAS relied not only on the transmitted X-ray intensity but also on the incident intensity, so it was less sensitive to the tube current change of the X-ray source and more robust than the traditional X-Ray thickness measurement, which only depended on the transmitted X-ray intensity. Additionally, PFM needed to calibrate the whole measuring range and even needed piece-wise calibration when the object was too thick, which caused a heavy workload. However, among the two neural nets, the LSTM model was more suitable for this counting task, as its evaluation results in Table 4 were much better than ANN. The reason was that LSTM made full use of the temporal sequence property in XAS data, as the sheets stacked one by one.
Furtherly, the total time of LSTM for data preprocessing and training was less than 263 sec., and the inference time was less than 0.006 sec., thus real- time stacked papers counting could be achieved. The weights of the LSTM could be saved in the file, and they could be reloaded to be used in the next prediction without training.
4. Conclusions
As an important operation in paper and printing industry, the stacked sheets counting is limited by current technical bottlenecks, such as breakage, low efficiency, and blur image. In this paper, a novel non-contact and real-time counting method was proposed, which used broadband XAS and LSTM. The results showed that LSTM had a better performance than the other two models (ANN, PFM). The MAE was 0.5197 sheets, MSE was 0.5236 sheets, MAXE was 1.8504 sheets, and R2 score was 0.9999, the single prediction time was less than 0.006 seconds. This method was non-destructive and less sensitive to the change in X-ray source tube current. It could be used in inline printing and packaging industry, and it is also applicable to the counting of other stacked substrates. In addition, a PCD with higher photon energy resolution would be used to measure broadband XAS with higher precision for further studies.
